CAT的使用和原理简介
CAT的使用和原理简介开发中刚好碰到了CAT的应用,利用这篇文章总结一下
![CAT的使用和原理简介]()
2019-08-07鱼鱼
造轮子1 注解管理
造轮子1 注解管理使用public @interface xxx{}可以自定义一个注解,在注解上面定义的注解叫做元注解 以下代码取自开源API文档生成项目Swagger: 在注解中也可以使用注解,我们称这些注解为元注解,上面代码中使用了一些比较常见的元注解 @Target({ElementType.TYPE})用于定义注解的使用范围,常见的包含 TYPE:类、接口、枚举 FIELD:字段声明 METHOD:方法声明 PARAMTER:参数声明 CONSTRUACTOR:构造函数声明 LOCAL_VARIABLE:局部变量声明 ANNOTATION_TYPE:其他注解声明 PACKAGE:包声明(代码中的第一行 声明package的时候)
![造轮子1 注解管理]()
2019-05-25鱼鱼
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)
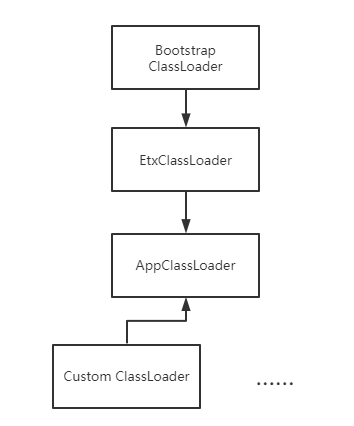
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)首先普及ClassLoader的基础:所有的Java类都是由ClassLoader由class文件加载进内存的,对于一个类,其唯一标识就是类名+加载他的ClassLoader(亦即对于不同的 ClassLoader,即使是加载了同一个Class也不能互通,本质上是两个类),其基本的分类如下图: BootstrapClassLoader是一个特殊的ClassLoader,负责启动时加载jre的类库 并不继承于ClassLoader,因为是jvm逻辑的一部分; ExtClassLoader也会加载jre类库,但是会加载那些额外的扩展类库(jre\lib\ext目录),到这个级别的 类加载器已经可以直接在代码中使用了;
2020-11-28鱼鱼
Springboot源码原理:从启动方法看配置加载
Springboot源码原理:从启动方法看配置加载首先看一个springboot项目的配置,我们可以定义一个application.yml,对于不同的环境有时也通过profile配置项指定不同的配置文件(譬如application-dev.yml),也可以通过命令行覆写具体的VM options配置项(举个栗子,启动时执行 java -jar xxx.jar --server.port=8080),此文讲解这些配制的读取原理 整体配置项的优先级从高到低为: 命令行配置; 系统属性(System.getProperties()) 系统环境变量 jar包外的主配置文件(带有) jar包内的主配置文件 jar包外的次要配置文件(由spring.profile指定的)

2021-03-09鱼鱼
MySQL tips
MySQL tips一些日常接触到的MySQL优化tips,比较散乱 假设有一个用户表,对于一句很简单的查询语句: 假设name与age字段均有单列索引,容易想到的是,MySQL应该会分别走两次索引,并将其结合起来,EXPLAIN也是如此,大多数时候MySQL会进行优化,我们可能会看到EXPLAIN的结果中有Using union或Using soft union,这是MySQL针对OR做了隐性的优化,但当SQL复杂或数据极端情况下,这一语句极容易变成全表扫描,偶尔使用联合索引可能解决问题,更多情况则是MySQL“昏了头”,即使OR条件均涉及数据条数不多,依旧没能在查询语句中使用索引,此时应调整为UNION语句(可以权衡一下重复及顺序是否有影响,可以使用更快的UNION ALL):

2021-01-13鱼鱼
Java中的数据结构
Java中的数据结构若不提到Jdk版本,本文中的源码都是基于jdk8版本分析的 注:有关同步集合(如Vector、ConcurrentHashMap、CopyOnWriteArrayList等)请移步博客 数组集合类,是Collection接口的子类,有序的Collection实现,包含ArrayList、LinkedList、Vector,其中Vector是线程安全的ArrayList,LinkedList是底层基于双向链表实现的List ArrayList的默认大小为10,扩容操作: 也就是1.5倍 不重复集合类,不能包含重复的元素,是Collection接口的子类,包含HashSet、LinkedHashSet、TreeSet,其实都是基于Map类的实现,所以详细了解请参阅Map类
2019-07-12鱼鱼
tips
tips一些小tip: 向上转型,失去特征 定义相同对象,重写hash和(不是或)equal Vue.nextTick() 回调函数:在Vue(重新)渲染页面之后调用 vue绑定样式,我们会发现background-color 不能直接绑定 需写为backgroundColor 因为js中不允许出现‘-’ 存库之前,mysql会把换行符什么的过滤掉,使得出入不一致(应用场景:textarea存)解决:this.value.replace(/\n|\r\n/g,"
") linux下的mysql的表名是区分大小写的! 实现线程接口 Runnable 注解注入失败 注解注入失败 Linux下缺少部分字体,使用drawString会出问题(二维码模块),解决手段:从windows引入字体,因为不是什么主流问题所以就简单写一下,如果再碰到相关问题在详细的讲述一下
![tips]()
2019-05-08鱼鱼
分布式系统中的CAP原则与BASE原则
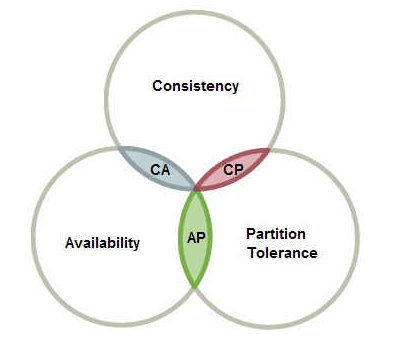
分布式系统中的CAP原则与BASE原则没有十全十美的分布式系统,分布式的痛点就在于各个节点状态的统一,CAP和BASE便是描述它的状态 本文中的分布式系统不仅指一套全是无状态的应用的服务系统,单纯依靠共享资源(如多个无状态的服务共用数据库或NoSQL而不在内存或是本身的服务容器中存储任何数据)运转的服务不是纯粹的分布式系统,分布式系统中一般需要包含有状态的服务(如主从同步的Mysql、多机哨兵模式的Redis、设置会话共享的分布式Tomcat服务) 图A 分布式架构雏形 ( 试想在上图中,若是网关通过A分区对数据做出了修改,此时还没有写入数据库但是A分区的缓存做出了调整,在分区容错的情况下A不能直接与B通信,那A与B分区就会失去一致性
2019-09-29鱼鱼
阻塞队列与Protobuf的Udp通信 - 基于Cat的代理(Agent)项目拆解
阻塞队列与Protobuf的Udp通信 - 基于Cat的代理(Agent)项目拆解CAT是美团点评的一个基于Java开发的异常和性能监控项目,github地址:https://github.com/dianping/cat 本篇文章不是对CAT本身的源码拆解,而是基于本人依赖CAT client开发的代理项目进行拆解,但是并不会纰漏任何技术细节 CAT当前已有很多不同语言的Client,当然暂且是不 CAT本身是通过CAT client收集数据并上报至CAT server,server会进行并,共有六种常见数据格式:Transaction、Event、Problem、Metric、HeartBeat、调用链标记,其实如果不考虑复杂的处理(譬如Metric是可以基于指标生成折线图,Problem可以根据具体的异常类型追溯到相应的会话Track)除去Transaction剩余的数据格式都可以理解为特殊的Event

2020-07-19鱼鱼
JVM源码解析(2) ContextClassLoader与ClassUtil.forName()方法浅析
JVM源码解析(2) ContextClassLoader与ClassUtil.forName()方法浅析在Spring获取Context的源代码中,我们看到了对ClassUtil的方法调用,通过给定ClassName和ClassLoader进行Class的加载: ClassUtil.forName是仅供于Spring内部使用的获取Class对象的方法,来看一下源码: 首先 对于缓存的Class一块,在类的静态块中就能看出其逻辑: 在上面的resolvePrimitiveClassName方法中,先对长度做了一个判断,因为较长的packagename会影响执行的性能: 最终加载Class依旧是通过ClassLoader的,先来看一下获取ClassLoader的方法实现: 此处优先使用了ContextClassLoader作为 类加载器而非默认的AppClassLoader,在JVM源码解析 从 Launcher类浅谈ClassLoader中,提到了关于 类加载器的相关知识,使用ContextClassLoader是为了弥补双亲委派加载机制的对于自定义 类加载器的缺憾:那些自定义的 类加载器并没有机会上场,在使用了AppClassLoader后我们的自定义ClassLoader所加载的Class是无法被加载进去的,使用ContextClassLoader,我们可以在定义线程时,通过Thread的init方法(子线程调用,私有方法)或是setContextClassLoader直接指定使用自定义的ClassLoader
![JVM源码解析(2) ContextClassLoader与ClassUtil.forName()方法浅析]()
2020-08-16鱼鱼
[Quick Start]使用RedisTemplate操作Redis
[Quick Start]使用RedisTemplate操作RedisRedisTemplate现在作为使用率最高的redis三方类库,隶属Spring技术栈,此篇文章意在指引RedisTemplate的快速上手 在实践前,请确保已经有一个可连接的Redis服务 Redis有五大基本数据类型:string、hash、list、set和zset string即是最单纯的k-v存储方式,使用set、get等指令 hash是哈希表的存储方式,比较适合用来存储对象,每一条value相当于Java的一个Map,使用hmset、hget等指令 list是简单的有序列表,每一条value相当于Java的一个List,使用lpush、lpop、rpush、rpop等指令
![[Quick Start]使用RedisTemplate操作Redis](/blog_cover/20200220/cdd943f261664778a1c746b93930db3a.png)
2020-02-23鱼鱼
待办事宜
待办事宜2018-10-18 解决XSS攻击问题(v-html) 针对缺省有所设置(blog:page等) 添加新增按钮 添加置顶 解决日志编辑首行出现空格 开发射线:一个匿名交流板 留言 联系方式 可回复 筑楼 时限性 超时关闭 匿名 默认匿名 字典: 可标注,添加富文本新组件字典(视情况添加 工作量难以预估 可考量在全网) 字典包括 可见性(待定),条目,解释,相关词条 必须可编辑 添加不同风格 参照http://www.unconstraint.cn/,github两种风格可切换 流动 简约 重金属 使用图床存储较大的图片(RECOMMEND:使用新浪微博)
![待办事宜]()
2019-03-24鱼鱼
