

所有原理实现基于Redis版本6.0.9。
hash在Redis中可以认为是套了一层的string,当然,对hash来说没有数字类型。让我们依旧通过基本命令看看hash的基本数据结构实现。
hash的相关指令实现
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
if ((c->argc % 2) == 1) {
addReplyErrorFormat(c,"wrong number of arguments for '%s' command",c->cmd->name);
return;
}
//在这一步会判断并在为空时进行创建
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
//此方法检查并转换类型
hashTypeTryConversion(o,c->argv,2,c->argc-1);
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
char *cmdname = c->argv[0]->ptr;
if (cmdname[1] == 's' || cmdname[1] == 'S') {
/* HSET */
addReplyLongLong(c, created);
} else {
/* HMSET */
addReply(c, shared.ok);
}
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
server.dirty++;
}
//创建hash
robj *hashTypeLookupWriteOrCreate(client *c, robj *key) {
robj *o = lookupKeyWrite(c->db,key);
if (checkType(c,o,OBJ_HASH)) return NULL;
if (o == NULL) {
o = createHashObject();
dbAdd(c->db,key,o);
}
return o;
}
robj *createHashObject(void) {
//其实创建了一个ziplist
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
在set方法中我们看到了hash的初始创建过程,一个hash最开始是zipist。
/* Check the length of a number of objects to see if we need to convert a
* ziplist to a real hash. Note that we only check string encoded objects
* as their string length can be queried in constant time. */
//在ziplist中有元素超长的时候转化为hash
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
for (i = start; i <= end; i++) {
//server.hash_max_ziplist_value是一个可配置项,默认64,即数组中有key或value长度大于64字节的时候会被转换为新格式->hashtasble
if (sdsEncodedObject(argv[i]) &&
sdslen(argv[i]->ptr) > server.hash_max_ziplist_value)
{
hashTypeConvert(o, OBJ_ENCODING_HT);
break;
}
}
}
void hashTypeConvert(robj *o, int enc) {
if (o->encoding == OBJ_ENCODING_ZIPLIST) {
//转换位hashtable
hashTypeConvertZiplist(o, enc);
} else if (o->encoding == OBJ_ENCODING_HT) {
serverPanic("Not implemented");
} else {
serverPanic("Unknown hash encoding");
}
}
void hashTypeConvertZiplist(robj *o, int enc) {
serverAssert(o->encoding == OBJ_ENCODING_ZIPLIST);
if (enc == OBJ_ENCODING_ZIPLIST) {
/* Nothing to do... */
} else if (enc == OBJ_ENCODING_HT) {
hashTypeIterator *hi;
dict *dict;
int ret;
hi = hashTypeInitIterator(o);
//利用dict数据格式
dict = dictCreate(&hashDictType, NULL);
while (hashTypeNext(hi) != C_ERR) {
sds key, value;
key = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_KEY);
value = hashTypeCurrentObjectNewSds(hi,OBJ_HASH_VALUE);
ret = dictAdd(dict, key, value);
if (ret != DICT_OK) {
serverLogHexDump(LL_WARNING,"ziplist with dup elements dump",
o->ptr,ziplistBlobLen(o->ptr));
serverPanic("Ziplist corruption detected");
}
}
hashTypeReleaseIterator(hi);
zfree(o->ptr);
o->encoding = OBJ_ENCODING_HT;
o->ptr = dict;
} else {
serverPanic("Unknown hash encoding");
}
}
想要了解ziplist可以看Redis原理-源码解析:数据结构2 list ,是为节省内存而生的链表格式。所以其实在使用ziplist时其查询的时间复杂度不是遵循hash的近似O(1),而是O(n),但是在数据量不大时,这种性能的损失微乎其微,并且能预见到大多数使用hash的场景都不会存储过多的字段。所以优先使用了更节省内存空间的ziplist。当元素过多或是过长时, 就会升级为dict数据格式,这也是Redis key所采用的存储方式,实现接近于hashtable。
dict
dict是一种hashtable的实现,看一下dict的定义:
typedef struct dict {
dictType *type; ///指向dictType的指针,这里面包含着对节点的各种操作
void *privdata; ///私有数据,保存着dictType结构中函数的参数
dictht ht[2]; ///一个dict中有两张哈希表
long rehashidx; ///如果rehashidx == -1,则没有进行rehash,标识rehash的进度
unsigned long iterators;///当前正在运行的迭代器数
} dict;
//这是我们的哈希表结构。 对于我们的旧表到新表,在实现增量重新哈希处理时,每个字典都有两个。
// 这个是hash表定义的数据结构
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;///字典的key值
union { ///定义value的共用体,他可以是一个指针、uint64、int64、double
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; ///该节点的下一个节点(拉链法hash冲突)
} dictEntry;
数据结构
整体数据结构如下图(图片来源Redis 数据结构 dict - Redis 源码日志 - 极客学院Wiki):
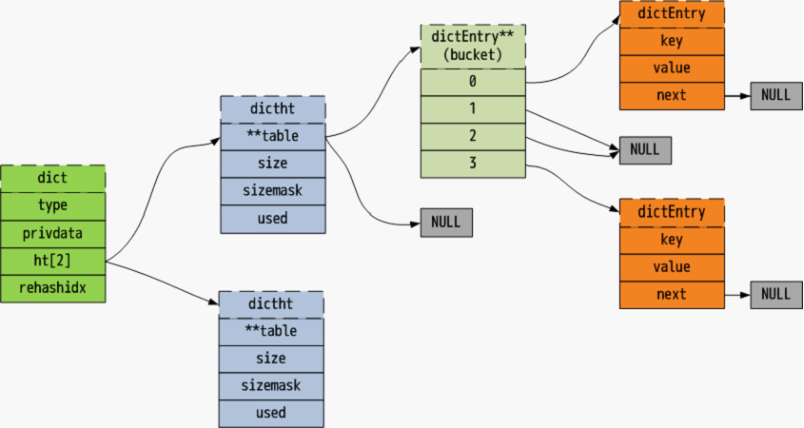
dictht才是真是正存储数据的地方。每次插入数据会对key进行hash演算,并插入对应的bucket,这样每次都对key进行hash然后查找的时间复杂度得以被压缩为近似O(1),当产生hash冲突时采用拉链法,即使用一个链表存储bucket相同的数据。
rehash&两组dictht
我们知道 当table中的数据个数/bucket数量的值越大,一个hash表便越容易产生冲突,当这一值达到Redis的扩容因子时(默认为1),Redis便会对bucket进行扩容操作,尽可能的避免冲突,提升查询性能。
rehash是一个不能被忽略的步骤,因其执行时间是无法预料的,可能涉及到大量数据的搬移,为了不使相关命令阻塞,Redis将一个dict写为两个dictht就是为rehash准备的。当触发rehash后,Redis会逐步进行数据的迁移(包括在每次执行相关命令时和定时执行)。其间会先为另一个空的dictht分配两倍的bucket内存用于扩容,然后再一步步迁移数据,所以在dict进行rehash操作时,需要通过迁移进度来判断要查询的数据在哪个表中,这样做会牺牲一些额外空间,但是换来了免于阻塞的rehash过程。
ps:这里采用hash算法是murmurhash,拉链冲突采用头插法
 2020-11-29鱼鱼
2020-11-29鱼鱼