MySQL tips
MySQL tips一些日常接触到的MySQL优化tips,比较散乱 假设有一个用户表,对于一句很简单的查询语句: 假设name与age字段均有单列索引,容易想到的是,MySQL应该会分别走两次索引,并将其结合起来,EXPLAIN也是如此,大多数时候MySQL会进行优化,我们可能会看到EXPLAIN的结果中有Using union或Using soft union,这是MySQL针对OR做了隐性的优化,但当SQL复杂或数据极端情况下,这一语句极容易变成全表扫描,偶尔使用联合索引可能解决问题,更多情况则是MySQL“昏了头”,即使OR条件均涉及数据条数不多,依旧没能在查询语句中使用索引,此时应调整为UNION语句(可以权衡一下重复及顺序是否有影响,可以使用更快的UNION ALL):

2021-01-13鱼鱼
多线程应用提高(III) 并发编程的艺术
多线程应用提高(III) 并发编程的艺术《并发编程的艺术》p36:JMM不保证64位的long型和double型变量的写操作具有原子性 面试中可能经常会被问到HashMap和HashTable的区别,其中最重要的就是前者并不是线程安全的,但其实在高并发的情形下,后者的效率低的不像话甚至不可用,所以在jdk7之后出现了线程高效且安全的ConcurrentHashMap 当并发严重时,某线程若是调用了同步方法,另外的线程将进入阻塞/轮询状态,既不能put也不能get,但ConcurrentHashMap是不同的,它采用了锁的分段技术,将数据分段存储,不同的数据持有不同的锁,这样可用性会大大高于HashTable,所以在实际开发中我们都用ConcurrentHashMap取代HashTable
![多线程应用提高(III) 并发编程的艺术]()
2019-06-18鱼鱼
Redis原理-源码解析:数据结构2 list
Redis原理-源码解析:数据结构2 list所有原理实现基于Redis版本6.0.9 Redis中的list采用的是链表,在开始前,我们先看看list的最基本指令实现 t-list.c 由此可知,Redis的List底层数据结构都是基于quickList的 这是list所依赖的数据结构: quicklist.h 我们注意到其是由quicklistNode所构成的链表,而其中的数据实则为zl(ziplist)或是bookmark,在大多时候quicklistNode都使用ziplist存储数据 在上文中lpush执行了一个插入方法quicklistPush,在quicklist.c中有他的实现: quicklist真正存储数据的结构是ziplist,所以倒不如说,在Redis中,list是一个由ziplist节点构成的链表

2020-11-28鱼鱼
算法:动态规划解法及例题
算法:动态规划解法及例题经历过很多算法题,其中最常见的解题方法便是动态规划 动态规划(dynamic programming,即DP),是一种常见的求解最优解的方案,他通过将复杂的问题拆分为单阶段的小问题求解,核心思想是递推,通过简单基础的解一步步接近最优解 对于一个算法问题,总有一个相对令人满意的解,但却不一定是我们想要的最优解,譬如在解决动态规划中最经典的背包问题时,有些人首先想到简单省心的贪心算法,取价值最高或是性价比最高的物品组合,这种方案得到的很有可能是最优解,但贪心的算法并不适用于动态规划领域,若是物品中恰好有能将背包塞得很满的组合,而采用贪心策略却浪费了很多背包空间 其实贪心策略本身更多也是一种“相对最优”的解决方案,而很少是真正的最优,这一点请务必斟酌
2020-03-11鱼鱼
数据库的并发、锁机制与MVCC
数据库的并发、锁机制与MVCC在日常开发中,经常遇到数据库进行高并发操作的情况,但是我们处理并发一般都只在代码范畴而并不处理具体的数据库操作,这是因为数据库对基本的数据库操作做了锁处理,让我们可以忽略这一层的并发问题 详细可以参考Mysql的官方文档 注意:这一篇博客是针对MySQL数据库,且实用默认的 引擎InnoDb,使用其他数据库可能存在略微的差异 MySQL默认的数据库引擎InnoDB中Autocommit值为0(即自动提交事务)执行SQL语句的时候,每一条SQL语句都是一条单独的事务,所以并不存在并发的问题,数据库的锁机制已经做了很好的处理 但是当我们开启事务时,若不加处理,可能会产生一系列并发带来的问题
2021-01-24鱼鱼
排坑指南-异步操作HttpServletRequest丢失Cookie
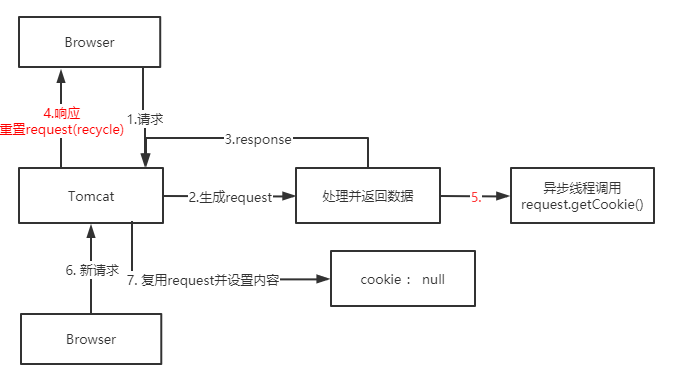
排坑指南-异步操作HttpServletRequest丢失Cookie遇到了一个很奇怪的bug:请求鉴权失败,因为通过Request对象获取到的Cookie中没有数据 经过debug调用request.getCookies()方法返回了null值,但是header属性的cookie却能拿到用户的有效cookie(request.getHeader("cookie")),其中缘由,且慢慢道来 我们可以在web项目中通过Request对象很方便的获取Cookie对象: 但其内部实现其实有一层缓存逻辑,从名为"cookie"的请求头中读取并处理数据转为Cookie对象并不是个省时事,在org.apache.catalina.connector.Request类中可以看到如下代码实现:
2020-11-11鱼鱼
对多线程的执行效率探究——合理的任务并发拆分
对多线程的执行效率探究——合理的任务并发拆分通常,我们选择多线程执行任务有两个理由,一是复杂任务采用多线程处理能够在发生并发时让用户减少等待也能防止阻塞,一是充分利用空闲时间,提高任务处理的效率,就后者而言,此处探讨不考虑客户端并发是否有必要把一个任务拆分成多线程来处理 为了探究多线程的效率问题,我做了一个实验,将不同种类的任务分别用单线程和多线程执行,同时也试验了不同种类的锁机制 测试基于Java 8的版本,希望看到总结可以直接点击到文末 开启五个线程执行任务,设定了足够次数的循环输出,输出的数字和当前线程,利用System.currentTimeMillis()统计任务用时 (代码略)以下是相同任务在不同环境下执行多次的平均执行时间

2019-12-09鱼鱼
网络协议面面观:TCP/IP协议组,TCP与UDP
网络协议面面观:TCP/IP协议组,TCP与UDP日常中的网站应用交互绝大部分都是基于TCP/IP协议栈构建的,而TCP/IP就是通信常见的protocol(协议)组,是一类协议的简称,利用这篇文章总结一些常见的TCP/IP网络协议簇以及着重一下两个常见的传输层协议TCP和UDP,扫一下盲 OSI参考模型是ISO(国际标准化组织)指定的网络互联七层模型,与此对比的还有互联网界针对TCP/IP协议簇提出的四层模型 相比之下,OSI七层模型的应用面很窄,且是一种理论模型,TCP/IP则是一种实施标准 一般使用四层模型来表达协议归属,所以此处不详细介绍七层模型的内容,只是简单的与四层协议做对比,两者对比: 应用层 通过这个TCP/IP模型,整体的数据流向是发送方自顶向下然后在接收方自底向上的,即:

2020-03-03鱼鱼
常见树形结构
常见树形结构树形结构 相关术语 结点(Node):表示树中的数据元素,由数据项和数据元素之间的关系组成 在图中,共有10个结点 结点的度(Degree of Node):结点所拥有的子树的个数,在图中,结点A的度为3 树的度(Degree of Tree):树中各结点度的最大值 在图中,树的度为3 叶子结点(Leaf Node):度为0的结点,也叫终端结点 在图中,结点E、F、G、H、I、J都是叶子结点 分支结点(Branch Node):度不为0的结点,也叫非终端结点或内部结点 在图中,结点A、B、C、D是分支结点 孩子(Child):结点子树的根 在图中,结点B、C、D是结点A的孩子

2019-03-15鱼鱼
IO多路复用模型:select、poll、epoll对比
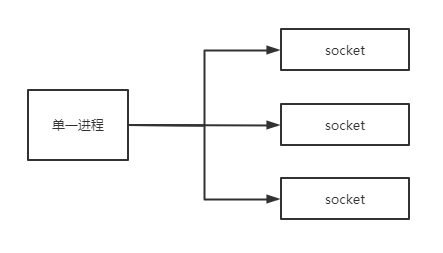
IO多路复用模型:select、poll、epoll对比我们平时提到的I/O几乎都是同步 阻塞模型,譬如网络请求的socket IO,在数据返回前,相应的线程或是进程将会一直 阻塞直到数据返回,比较直接的处理便是针对IO流一对一的监听,但在IO返回前,相应的系统资源会平白无故的浪费,这种处理方式会大大降低服务器的吞吐 如果我们用很少的线程来监听这些IO,就能实现对系统资源的更好利用,在相应的socket有数据返回时才去读取数据 这种方式被称作IO多路复用,在Linux系统中,实现IO多路复用的方式(从古老到新)有select、poll和epoll 现在很多中间件都使用epoll IO多路复用模型才因此有着很高的性能和吞吐 此处简单描述三种方式的实现和区别
2020-08-11鱼鱼
造轮子2 灵活运用反射
造轮子2 灵活运用反射//TODO
![造轮子2 灵活运用反射]()
2019-05-25鱼鱼
ES快速入门(2)——Tokenizer、Reindex
ES快速入门(2)——Tokenizer、Reindex本篇介绍es提供的几种分词分析器和常用的开源分词分析器 es默认的分词器,中规中矩的按照 Unicode Standard Annex #29分词,一般的小写符号会忽略,对于中文等字符会逐字分割,参数max_token_length表示最大的字符长度,再切分后会继续按此切分 譬如: 会分词为: 一个无视语义,按照字符尽量收集全索引的分词方式,会前后叠加的按符号位分词,参数: 会分词为: nGram的分词很全面,但如此夸张的方式用不好会导致索引doc过大,同时使查询效率偏低 分词规则很简单,无其余规则的按空格分词: 会分词为: 在standard的基础上能够有效拆分出邮箱和url地址的格式,同样有max_token_length这一参数:
![ES快速入门(2)——Tokenizer、Reindex]()
2020-09-05鱼鱼
