网络协议面面观:TCP/IP协议组,TCP与UDP
网络协议面面观:TCP/IP协议组,TCP与UDP日常中的网站应用交互绝大部分都是基于TCP/IP协议栈构建的,而TCP/IP就是通信常见的protocol(协议)组,是一类协议的简称,利用这篇文章总结一些常见的TCP/IP网络协议簇以及着重一下两个常见的传输层协议TCP和UDP,扫一下盲 OSI参考模型是ISO(国际标准化组织)指定的网络互联七层模型,与此对比的还有互联网界针对TCP/IP协议簇提出的四层模型 相比之下,OSI七层模型的应用面很窄,且是一种理论模型,TCP/IP则是一种实施标准 一般使用四层模型来表达协议归属,所以此处不详细介绍七层模型的内容,只是简单的与四层协议做对比,两者对比: 应用层 通过这个TCP/IP模型,整体的数据流向是发送方自顶向下然后在接收方自底向上的,即:

2020-03-03鱼鱼
数据库的存储过程、触发器和一些语法
数据库的存储过程、触发器和一些语法本篇文章讲述基于MySQL的存储过程触发器和一些相关的语法 在数据库中,存储过程是指将复用度很高并且不需要通过程序进行预编译的的SQL语句预先写好存放起来(此处所指的为用户定义在数据库中的存储过程),在需要时直接通过call调用 先看一个例子(注意,这不是创建存储过程的语句): 其中使用了日期相关的函数,DATE_SUB(CURDATE(),INTERCAL 10 DAY)代表当前时间前推十天 这个存储过程作用是查出十天前的数据然后将其删除 MySQL默认的分隔符是" ; ",这样一来定义存储过程就会因为 ; 被打断,所以在定义存储过程前后需要修改分隔符,使用DELIMITER关键字跟随分隔符,实际创建存储过程语句为:
![数据库的存储过程、触发器和一些语法]()
2019-06-12鱼鱼
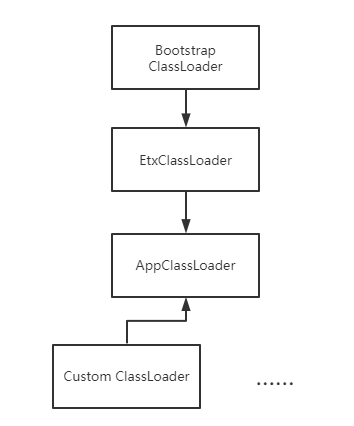
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)首先普及ClassLoader的基础:所有的Java类都是由ClassLoader由class文件加载进内存的,对于一个类,其唯一标识就是类名+加载他的ClassLoader(亦即对于不同的 ClassLoader,即使是加载了同一个Class也不能互通,本质上是两个类),其基本的分类如下图: BootstrapClassLoader是一个特殊的ClassLoader,负责启动时加载jre的类库 并不继承于ClassLoader,因为是jvm逻辑的一部分; ExtClassLoader也会加载jre类库,但是会加载那些额外的扩展类库(jre\lib\ext目录),到这个级别的 类加载器已经可以直接在代码中使用了;
2020-11-28鱼鱼
浅谈锁机制、主流锁设计方案
浅谈锁机制、主流锁设计方案本文旨在探讨通用的锁机制实现逻辑,以Java中常见的锁实现为例 本文提到的锁,是指通过限制并发/并行访问所添加的安全措施,本质上是通过限制线程/进程同时更改数据或是读取数据与写入数据产生时序差从而造成数据问题 锁机制中,有一些常见特性: 可重入性 指同一线程/进程携带相同的标识可以反复多次加锁,每次加锁和释放锁对应的重入次数+1/-1; 读写锁/独享共享 是锁的不同运作模式,分为读写锁,读锁与写锁、写锁与写锁是互斥的,但多个线程/进程可以同时对一个逻辑添加读锁,独享共享是另一种叫法 公平性 锁分为 公平锁和非 公平锁, 公平锁指锁释放和获取的顺序严格按照索取的顺序,非 公平锁则是等待锁的对象共同进行锁释放机会的争抢
![浅谈锁机制、主流锁设计方案]()
2024-10-15鱼鱼
DDD领域下的架构模式——CQRS架构
DDD领域下的架构模式——CQRS架构//TODO
![DDD领域下的架构模式——CQRS架构]()
2021-06-24鱼鱼
使用Shiro和token进行无状态登录
使用Shiro和token进行无状态登录我们之前可以使用shiro实现登录,但这些都是基于session或是cookie实现的,这些只能用于单机部署的服务,或是分布式服务共享会话,显然后者开销极大,所以JWT(JSON Web Token)应运而生,JWT是一套约定好的认证协议,通过请求携带令牌来访问那些需鉴权的接口 我们在这里使用token,原理类似,但是规则更为简单,没有形式上的约束,只是在请求Head或是body中添加token用于校验用户身份,token是可以和会话共存的,此处我们使用Shiro的会话登录结合JWT来实现无状态登录,从而实现扫码登录和一般的接口访问授权 项目中,需要实现无状态登录(单点登录,SSO),但是同时也要保持Shiro本身自带的会话登录
![使用Shiro和token进行无状态登录]()
2020-03-22鱼鱼
分布式系统中的一致性算法和问题解决
分布式系统中的一致性算法和问题解决在撰写脑裂问题相关的博客时发现脑裂问题的产生原因在不同算法下的分布式系统各不相同,需要先大致了解一致性算法并针对性的解决 市面上有很多开源的分布式系统,他们的数据一致性算法不尽相同,例如k-v系统的祖师爷——zookeeper采用的是ZAB的算法,而最近流行的Consul是raft算法,不同数据中心server沟通的方式则是gossip协议 不同的协议和方式对选举和数据同步有不同的处理机制,利用这篇文章来对比常见的分布式一致性算法 一个系统可能会使用多个不同的一致性算法,以便于在不同的业务环节上有着各自更贴切的处理 ps:有种观点是一致性算法不是很准确,因为replica也能保证数据某种程度上具有一致性,有人称之为共识算法
2021-03-13鱼鱼
Redis原理-源码解析:数据结构3 sorted set(zset))
Redis原理-源码解析:数据结构3 sorted set(zset))Redis的set数据结构在此不多讲,同Java中原理一样,set也可以理解为是hash剥离了value的数据结构,即同为dic 但是zset(有序集合)其实在底层原理上完全不同于set 所有原理实现基于Redis版本6.0.9 先看一下基本的指令实现,着重注意中文注解的地方 t_zset.c 可以看出zset的数据结构不是固定的,在其元素数或是元素的字符串过长时,其结构为zset;否则使用ziplist数据结构(像hash一样为了节省空间),二者的创建方法如下: ziplist的代码和原理可以参考我的博客Redis原理-源码解析:数据结构2 list-鱼鱼的Java小站,就是一个节省内存的压缩的链表结构

2021-02-28鱼鱼
造轮子2 灵活运用反射
造轮子2 灵活运用反射//TODO
![造轮子2 灵活运用反射]()
2019-05-25鱼鱼
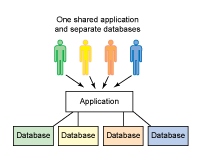
动态路由数据源(多租户)解决方案
动态路由数据源(多租户)解决方案当下有很多服务都使用了多数据源,或是出于跨库查询或是分库分表、读写分离等,多数据源解决方案早已不是稀罕事 常见的解决方案包括使用多数据源框架(例如Shareding-Jdbc)、在数据库端做代理(例如MYCAT)、对于固定的几个数据源连接,也可以直接手动配置多个数据源,这种相关处理有很多源码,我在github上也有简单的实现:fishstormX/dynamicDataSource: 动态数据源的实现,基于maven自定义多模块骨架 Spring Boot2.0.x,本文实现的是动态数据源,主要为了解决 多租户问题(不同的用户群组有不同的数据源和配置,强调数据的隔离性) 本文技术能实现的是动态数据源,基于Spring框架,即能够将注入的Datasource根据租户不同使用不同的来源,同时根据租户增减动态的增删和缓存数据源(增是因为会有新增租户可能使用到项目启动后的数据源,减是因为租户数不可预料,不可直接缓存所有的数据源)
2021-01-07鱼鱼
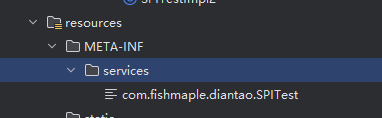
Java的SPI机制
Java的SPI机制SPI(Service Provider Interface) 是JDK内部提供的一种用于服务能力扩展的机制 在服务中通过不同的下沉方法实现能够加载不同的接口实现类,从而实现功能的热插拔 相比一些类似的设计模式(例如策略模式), SPI作为Java自带的实现特性,相对更加灵活和开放 我们常见的JDBC、日志框架slf4j、JavaMail、Spring等组件都基于 SPI实现(例如JDBC针对不同数据源的驱动) 之所以说区别于Java的一些设计模式,因为Java有一些实现能实现 SPI的动态加载 首先让我们定义 SPI对外提供抽象能力的接口类,这里为了便于理解展示包路径:
2024-10-14鱼鱼
算法:深度优先搜索(DFS)
算法:深度优先搜索(DFS)在算法:广度优先搜索(BFS)(最短路径)中,我们提到了按照广度优先遍历的搜索方式,使用队列作为常规的搜索方式,与之相对应的为深度优先搜索(DFS) 如果说BFS对应着树结构的前中后序遍历 但是DFS相对解法较为多元一些,有些时候不得不使用递归进行求解 同时,有很多求解只是进行图的遍历,不关心是广度还是深度优先,其解都是相同的 在这里我们暂且不讨论的基于栈而是侧重基于递归的遍历实现 对于二叉树,最常见的遍历方式有前序(又称 先序)遍历、中序遍历、后序遍历、层次遍历 前中后序只为取得的值先后顺序不同,即递归有先后 依赖栈实现的的深度优先是前序遍历 以下是一个二叉树的前序遍历代码实现:
![算法:深度优先搜索(DFS)]()
2020-06-27鱼鱼
