

Redis的set数据结构在此不多讲,同Java中原理一样,set也可以理解为是hash剥离了value的数据结构,即同为dic。但是zset(有序集合)其实在底层原理上完全不同于set。
所有原理实现基于Redis版本6.0.9。
创建命令实现分析数据结构
先看一下基本的指令实现,着重注意中文注解的地方。
t_zset.c
void zaddCommand(client *c) {
zaddGenericCommand(c,ZADD_NONE);
}
void zaddGenericCommand(client *c, int flags) {
static char *nanerr = "resulting score is not a number (NaN)";
robj *key = c->argv[1];
robj *zobj;
sds ele;
double score = 0, *scores = NULL;
int j, elements;
int scoreidx = 0;
int added = 0;
int updated = 0;
int processed = 0;
scoreidx = 2;
while(scoreidx < c->argc) {
char *opt = c->argv[scoreidx]->ptr;
if (!strcasecmp(opt,"nx")) flags |= ZADD_NX;
else if (!strcasecmp(opt,"xx")) flags |= ZADD_XX;
else if (!strcasecmp(opt,"ch")) flags |= ZADD_CH;
else if (!strcasecmp(opt,"incr")) flags |= ZADD_INCR;
else if (!strcasecmp(opt,"gt")) flags |= ZADD_GT;
else if (!strcasecmp(opt,"lt")) flags |= ZADD_LT;
else break;
scoreidx++;
}
int incr = (flags & ZADD_INCR) != 0;
int nx = (flags & ZADD_NX) != 0;
int xx = (flags & ZADD_XX) != 0;
int ch = (flags & ZADD_CH) != 0;
int gt = (flags & ZADD_GT) != 0;
int lt = (flags & ZADD_LT) != 0;
elements = c->argc-scoreidx;
if (elements % 2 || !elements) {
addReply(c,shared.syntaxerr);
return;
}
elements /= 2; /* Now this holds the number of score-element pairs. */
if (nx && xx) {
addReplyError(c,
"XX and NX options at the same time are not compatible");
return;
}
if ((gt && nx) || (lt && nx) || (gt && lt)) {
addReplyError(c,
"GT, LT, and/or NX options at the same time are not compatible");
return;
}
if (incr && elements > 1) {
addReplyError(c,
"INCR option supports a single increment-element pair");
return;
}
scores = zmalloc(sizeof(double)*elements);
for (j = 0; j < elements; j++) {
if (getDoubleFromObjectOrReply(c,c->argv[scoreidx+j*2],&scores[j],NULL)
!= C_OK) goto cleanup;
}
/* Lookup the key and create the sorted set if does not exist. */
zobj = lookupKeyWrite(c->db,key);
if (checkType(c,zobj,OBJ_ZSET)) goto cleanup;
//判断数据大小并选择数据类型
if (zobj == NULL) {
if (xx) goto reply_to_client;
//server.zset_max_ziplist_entries 可配置,最小节点数 默认128
//server.zset_max_ziplist_value 可配置,最小字符串 默认64
if (server.zset_max_ziplist_entries == 0 ||
server.zset_max_ziplist_value < sdslen(c->argv[scoreidx+1]->ptr))
{
//节点多或字符串大时,创建zset
zobj = createZsetObject();
} else {
//创建ziplist
zobj = createZsetZiplistObject();
}
dbAdd(c->db,key,zobj);
}
//遍历要插入的数据
for (j = 0; j < elements; j++) {
double newscore;
//第j条数据的score
score = scores[j];
int retflags = flags;
ele = c->argv[scoreidx+1+j*2]->ptr;
//调用zadd 实际执行插入的地方
int retval = zsetAdd(zobj, score, ele, &retflags, &newscore);
if (retval == 0) {
addReplyError(c,nanerr);
goto cleanup;
}
if (retflags & ZADD_ADDED) added++;
if (retflags & ZADD_UPDATED) updated++;
if (!(retflags & ZADD_NOP)) processed++;
score = newscore;
}
server.dirty += (added+updated);
reply_to_client:
if (incr) { /* ZINCRBY or INCR option. */
if (processed)
addReplyDouble(c,score);
else
addReplyNull(c);
} else { /* ZADD. */
addReplyLongLong(c,ch ? added+updated : added);
}
cleanup:
zfree(scores);
if (added || updated) {
signalModifiedKey(c,c->db,key);
notifyKeyspaceEvent(NOTIFY_ZSET,
incr ? "zincr" : "zadd", key, c->db->id);
}
}
可以看出zset的数据结构不是固定的,在其元素数或是元素的字符串过长时,其结构为zset;否则使用ziplist数据结构(像hash一样为了节省空间),二者的创建方法如下:
//元素不大
robj *createZsetObject(void) {
//创建了一个zset结构
zset *zs = zmalloc(sizeof(*zs));
robj *o;
//为zset创建一个dict
zs->dict = dictCreate(&zsetDictType,NULL);
//为zset创建一个skiplist
zs->zsl = zslCreate();
o = createObject(OBJ_ZSET,zs);
o->encoding = OBJ_ENCODING_SKIPLIST;
return o;
}
//元素过大
robj *createZsetZiplistObject(void) {
//新建ziplist 没什么好说的
unsigned char *zl = ziplistNew();
robj *o = createObject(OBJ_ZSET,zl);
o->encoding = OBJ_ENCODING_ZIPLIST;
return o;
}
ziplist的代码和原理可以参考我的博客Redis原理-源码解析:数据结构2 list-鱼鱼的Java小站,就是一个节省内存的压缩的链表结构。这里着重分析skiplist。
zset
这是zset的数据结构,包括一个skiplist和一个dic:
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
其中zskiplist是跳跃表,用于存储skiplist的数据,dict用于存储value和score的映射指针,是一个冗余的结构,以便于以O(1)的时间复杂度查询score;
skiplist
zskiplist的数据结构其实就是一个以链表为基础的跳跃表:
//level代表最高的层数
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
//可能有多个向后的链表,span表示跨度
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
skiplist是在链表的基础上,每个节点有不定数量的指针指向后面的跨越了多个的链表节点。大致结构如图:
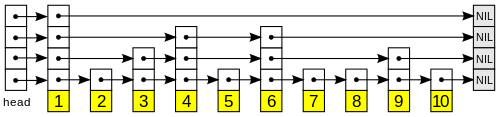
图1 skiplist结构举例
可以看到每一个节点的指针数(高度)是非常随机的。
插入数据源码逻辑
通过插入数据的源码,我们可以看到查找元素和生成随机高度的逻辑。在插入时,判断是新数据并且是zset数据结构,会执行如下代码:
int zsetAdd(robj *zobj, double score, sds ele, int *flags, double *newscore) {
//…………
zset *zs = zobj->ptr;
zskiplistNode *znode;
dictEntry *de;
//……
ele = sdsdup(ele);
//插入数据
znode = zslInsert(zs->zsl,score,ele);
serverAssert(dictAdd(zs->dict,ele,&znode->score) == DICT_OK);
*flags |= ZADD_ADDED;
if (newscore) *newscore = score;
return 1;
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
//暂存遍历中的前一个节点以便于插入
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
/上述前一个节点的排名(跳跃表节点从小到达排序,遍历过程中跨度的累计值即为遍历节点的排名)
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
//从高层向低层查找插入节点的前一节点
// 这个遍历是单向的 如果会一直遍历到最下层链表
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
//若遍历的节点存在前向节点,并且节点均小于插入节点, 继续循环,直至找到插入节点的前向节点
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
//继续向后遍历 推算span
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
//随机生成层数,方法在下面
level = zslRandomLevel();
if (level > zsl->level) {
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele);
//插入节点
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
//更新跨度值
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) {
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
}
//生成层数 这里的ZSKIPLIST_MAXLEVEL是32 ,很足够用了
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
即如果我们在上面的图1数据结构中试图找节点10(这样称score为10的节点),则顺序为:
第4层节点1->第3层节点1->第3层节点4->第3层节点6->第2层节点6->第2层节点9->第1层节点9->第1层节点10
上下层切换可以忽略不计,我们总共跳跃4次变找到了节点10,相比最下层节省了很多时间。
总结
Redis中的sorted set采用了ziplist(当元素没那么多字符串没那么大时),以便于节省内存,这一点和hash类似,此种情况下查询时间复杂度为O(n),但是一般都不是太大的数据影响不大。
当数据达到一定大小时,便会从ziplist转换为zset,其包含一skiplist和dic,dic主要存储键值和score的映射,以便于在O(1)的效率下查询score。skiplist主要是一个多排链表,一个节点可能存储了向后推进多个元素的指针,使用skiplist做插入查询的时候,会从最高层逐渐遍历到最下层,一般都能有效缩短查询时间,每一个节点的高度都是完全随机生成的1-32。
 2021-02-28鱼鱼
2021-02-28鱼鱼