

此篇文章探讨MySQL数据库的锁,讨论MySQL各种语句将如何加锁,以及加锁的“效果”,主要针对默认的InnoDb引擎。基于MySQL5.6之后的版本。
有心力的可以直接看MySQL官方文档,说的更为详细:14.7.3由InnoDB中的不同SQL语句设置的锁
锁分类
按类型分,MySQL有锁:
行锁,最普通的锁,其实是加在索引上的锁。
表锁,直接加在整张表的锁,一旦上锁整张表的操作都会比较锁。
间隙锁,又称GAP锁,用于在涉及范围查询时给莫须有的位置加锁,防止并发插入等操作出现数据不一致(诸如幻读)的问题。间隙锁之间是不会冲突的。行锁与Gap锁合称Next-Key锁。间隙锁只能锁住间隙,即间隙锁不能指定具体的数据范围,将会锁上整个间隙。
所有的加锁对象除去索引便是表锁,MySQL不存在数据本身加锁一说,即,如果WHERE语句不走索引,则只能加表锁。
间隙锁不会存在于RC隔离级别中。
按模式分,MySQL有5种锁:
InnoDB 实现了以下两种类型的行锁:
共享锁(S):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁。
排他锁(X):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁。
为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB 还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁:
意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
还有插入时使用的锁:
插入意向锁:用于数据插入的Gap锁,表明要插入的意图,都是单行的锁,意向锁之间互相等待,上锁过程不受其他锁影响(当然插入行为会阻塞),主要为了在同一范围区间如果已有间隙锁插入数据不冲突不互相阻塞。
查询加锁
由于MySQL使用了
通过如下语句,可以给查询语句的扫描行上共享锁:
select ... lock in share mode
通过如下语句,可以给查询语句的扫描行上排它锁:
select ... for update //排他锁
更新加锁
UPDATE-有索引
UPDATE语句加锁很好概括:根据语句涉及的索引及聚簇索引上锁。使用EXPLAIN查看相应的查询语句可以很容易地看出所走的索引。譬如有如下一个表user,其name列有单列索引,email列有唯一索引:

接下来执行下面的语句:
UPDATE user set registertime = "0" WHERE name = '小明'
假设表中数据有一定量级和复杂度,在更新时就会走索引列name,就会对name的索引值为"小明"的节点上X锁,同时回溯主键id,对相应的记录上X锁。
UPDATE-无索引
无索引时很多人认为MySQL的更新会使用表锁,实际上为了尽可能的避免阻塞,是涉及了整个表的行锁。这与表锁有何不同呢?因为MySQL会在获取数据的时候对数据做比较,如果上面的SQL语句中name列并没有索引,MySQL起初会对所有聚簇索引列上锁,并在其后在循环过程中逐渐对数据列做解锁操作。当然,这也是批量无索引的状态下更新很容易引起死锁的原因。
插入加锁
INSERT(死锁的产生)
普通的插入操作会先对待加行加插入意向锁(为了避免同个间隙有多个GAP锁),当发生唯一索引(主键索引)冲突时,即待插入列有排它锁(为什么不直接回滚?因为可能有一个事务正在尝试删除此列或是一个已经插入数据的事务之后会回滚),会等待并在其后尝试插入共享锁。直到没有锁冲突,当前事务会插入数据并对其上排它锁。
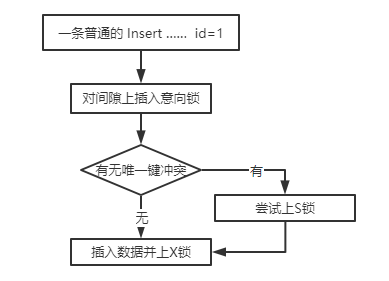
由此看来,只要存在多个彼此冲突的插入列并发执行,是会触发死锁的,我们以官方文档上的例子来说:
CREATE TABLE t1 (i INT, PRIMARY KEY (i)) ENGINE = InnoDB; #t1 START TRANSACTION; INSERT INTO t1 VALUES(1); #t2 START TRANSACTION; INSERT INTO t1 VALUES(1); #t3 START TRANSACTION; INSERT INTO t1 VALUES(1);
在RR隔离级别中,假设t1先执行,并且在插入后回滚了,回滚前由于i为1的记录上有X锁,t2和t3检测到冲突,只能尝试上S锁。由于t2和t3均持有插入意向锁,在上S锁的时候会陷入相互等待的局面,从而造成死锁。
如果同时涉及两个唯一索引,这一问题将更加严重,因为考虑到加锁顺序也有所不同,针对并发插入应慎重处理。
INSERT…… ON DUPLICATE KEY UPDATE语句上锁情况类似,唯一不同的是尝试上的不是S锁而是X锁。
REPLACE操作在冲突时则是会对行上Next-Key锁、
 2021-02-05鱼鱼
2021-02-05鱼鱼