

所有原理实现基于Redis版本6.0.9。
List相关命令实现初探
Redis中的list采用的是链表,在开始前,我们先看看list的最基本指令实现。
t-list.c
#define LIST_HEAD 0
#define LIST_TAIL 1
void lpushCommand(client *c) {
pushGenericCommand(c,LIST_HEAD);
}
void pushGenericCommand(client *c, int where) {
int j, pushed = 0;
//查找值和验证数据类型
robj *lobj = lookupKeyWrite(c->db,c->argv[1]);
if (checkType(c,lobj,OBJ_LIST)) {
return;
}
for (j = 2; j < c->argc; j++) {
//为空创建quicklist并配置
if (!lobj) {
lobj = createQuicklistObject();
quicklistSetOptions(lobj->ptr, server.list_max_ziplist_size,
server.list_compress_depth);
dbAdd(c->db,c->argv[1],lobj);
}
//插入值
listTypePush(lobj,c->argv[j],where);
pushed++;
}
addReplyLongLong(c, (lobj ? listTypeLength(lobj) : 0));
//后续通知等操作
if (pushed) {
char *event = (where == LIST_HEAD) ? "lpush" : "rpush";
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_LIST,event,c->argv[1],c->db->id);
}
server.dirty += pushed;
}
//插入值,调用quicklistPush
void listTypePush(robj *subject, robj *value, int where) {
if (subject->encoding == OBJ_ENCODING_QUICKLIST) {
int pos = (where == LIST_HEAD) ? QUICKLIST_HEAD : QUICKLIST_TAIL;
value = getDecodedObject(value);
size_t len = sdslen(value->ptr);
quicklistPush(subject->ptr, value->ptr, len, pos);
decrRefCount(value);
} else {
serverPanic("Unknown list encoding");
}
}
void lindexCommand(client *c) {
robj *o = lookupKeyReadOrReply(c,c->argv[1],shared.null[c->resp]);
if (o == NULL || checkType(c,o,OBJ_LIST)) return;
long index;
robj *value = NULL;
if ((getLongFromObjectOrReply(c, c->argv[2], &index, NULL) != C_OK))
return;
if (o->encoding == OBJ_ENCODING_QUICKLIST) {
quicklistEntry entry;
if (quicklistIndex(o->ptr, index, &entry)) {
if (entry.value) {
value = createStringObject((char*)entry.value,entry.sz);
} else {
value = createStringObjectFromLongLong(entry.longval);
}
addReplyBulk(c,value);
decrRefCount(value);
} else {
addReplyNull(c);
}
} else {
serverPanic("Unknown list encoding");
}
}
由此可知,Redis的List底层数据结构都是基于quickList的。
quicklist
这是list所依赖的数据结构:
quicklist.h
//整体是一个双向链表
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; // ziplist表节点数量
unsigned long len; // 节点个数
int fill : QL_FILL_BITS; // fill factor for individual nodes
unsigned int compress : QL_COMP_BITS; // 压缩的程度 0为不压缩
unsigned int bookmark_count: QL_BM_BITS; //结尾书签
quicklistBookmark bookmarks[];
} quicklist;
/*
* 32字节的结构,链表节点
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl; //实际数据,指向ziplist或是quicklistLZF
unsigned int sz; // ziplist大小
unsigned int count : 16; //ziplist节点数
unsigned int encoding : 2; //编码格式,1表示进行LZF分节点压缩,2不压缩使用原生字节
unsigned int container : 2; // 2表示采用ziplist
unsigned int recompress : 1; //节点压缩状态 为1表示等待被压缩
unsigned int attempted_compress : 1; //测试
unsigned int extra : 10; //预留额外空间
} quicklistNode;
//书签 用于比较大的链表,加快查询速度
typedef struct quicklistBookmark {
quicklistNode *node;
char *name;
} quicklistBookmark;
我们注意到其是由quicklistNode所构成的链表,而其中的数据实则为zl(ziplist)或是bookmark,在大多时候quicklistNode都使用ziplist存储数据。在上文中lpush执行了一个插入方法quicklistPush,在quicklist.c中有他的实现:
void quicklistPush(quicklist *quicklist, void *value, const size_t sz,
int where) {
if (where == QUICKLIST_HEAD) {
quicklistPushHead(quicklist, value, sz);
} else if (where == QUICKLIST_TAIL) {
quicklistPushTail(quicklist, value, sz);
}
}
/* Add new entry to head node of quicklist.
* 在头部插入
* Returns 0 if used existing head.
* Returns 1 if new head created. */
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head;
//判断头部的ziplist是否还能够插入,实际是判断ziplist的空间,这里暂且略过
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
//执行ziplistPush
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(quicklist->head);
} else {
//创建了一个新的ziplist并插入
quicklistNode *node = quicklistCreateNode();
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node);
_quicklistInsertNodeBefore(quicklist, quicklist->head, node);
}
quicklist->count++;
quicklist->head->count++;
return (orig_head != quicklist->head);
}
ziplist
quicklist真正存储数据的结构是ziplist,所以倒不如说,在Redis中,list是一个由ziplist节点构成的链表。
ziplist更接近于数组,其内存空间连续并且预分配内存。只是没有存储相应的内存偏移量(对于短小的ziplist这一行为显得多余),需要从头遍历。在ziplist中有很多描述这一数据结构的注释。主要翻译如下:
ziplist是经过特殊编码的双向链接列表,旨在提高内存效率。 它存储字符串和整数值,其中整数被编码为实际整数,而不是一系列字符。 * 它允许在O(1)时间在列表的任一侧进行推和弹出操作。 但是,由于每个操作都需要重新分配zip列表使用的内存,因此实际的复杂性与 * zip列表使用的内存量有关。
ziplist的总体布局如下:
头部节点 | 真实节点数据 | 结尾标志
<zlbytes> <zltail> <zllen> | <entry> <entry> ... <entry> | <zlend>
ziplist中的数据entry结构如下:
前一个节点长度 | 编码格式 (决定如何进行压缩) | 节点数据
<prevlen> | <encoding> | <entry-data>
entry中的prevlen是为了便于ziplist可以在entry节点中进行遍历。
对于ziplist的定义并非一个对象,而是直接以char形式存储,所以我们只能通过注释了解其大致原理:
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) {
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
zl[bytes-1] = ZIP_END;
return zl;
ziplist的一些参数可以通过Redis进行调整,包括是否全压缩,ziplist默认空间等。
为什么采用ziplist
这样的数据结构可以对数据进行有效压缩,如果单单采取quicklist的链表形式存储数据会比较浪费存储空间,尤其是对于Redis这种一般数组元素不是很大的存储,若是采用链表(假设quicklist每一个节点都存储一条数据),由于前后指针的存在,其内存空间的占用是很大的,而且内存不连续性也导致寻址较慢。所以加上了ziplist更加节省宝贵的内存空间。当然ziplist的弊端显而易见,它与数组相同,若是在中间进行插入或删除操作使得整个ziplist数据存储区域发生位移,就有小概率可能发生“连锁更新”(类比数组重分配内存,循环进行内存重分配),因此ziplist的数据插入行为时间复杂度为O(n)~O(n²)。所以Redis采用了查询较快的quicklist和节省内存的ziplist,在节省内存空间的同时尽可能的优化时间复杂度。
链表?数组?list的正确用法
Redis的list跟原本想象的有些不同,为了插入效率和更好的内存利用,显然它更接近于一个"LinkedList",诸如lindex和lrange、linsert等命令也就不是很推荐使用,尤其对于一些较长的list。以下是常用list命令的预估时间复杂度(详细的复杂度解释可以去官网查询):
| 命令 | 时间复杂度 | 解释 |
| lpush、rpush | O(1) | 在list两端做插入操作,时间复杂度为1 |
| rpop、lpop | O(1) | 在list两端做删除操作,时间复杂度为1 |
| llen | O(1) | 直接获取存储的list长度 |
| lindex | O(n) | 遍历到第n位获取元素,不推荐使用 |
| lrange |
O(n+s) | 遍历到第n位然后继续遍历到s,一般不建议使用 |
| linsert |
O(n) | 遍历到第n位插入,不推荐使用 |
| lrem |
O(n+m) | 遍历到第n位删除,m为删除的元素数,不推荐使用 |
因此对于list尽可能不要使用随机访问和更新相关的命令。即使要使用,也应用注入lrange等的批量操作。
总结
Redis中的list数据构成如下(来源博客Redis源码剖析和注释(七)--- 快速列表(quicklist)):
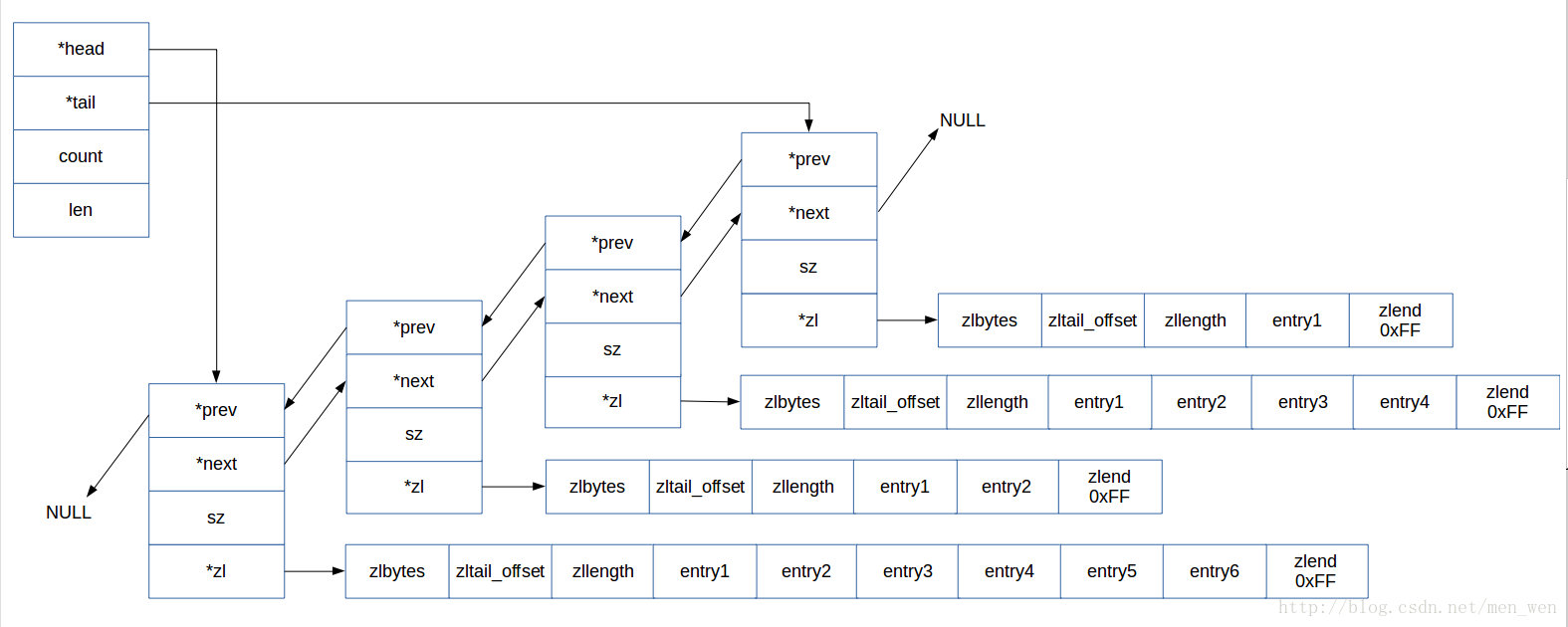
通过使用quicklist和ziplist,在性能和内存占用上进行了权衡。quick整体是分散内存空间,链表结构,数据修改较快,但是指针结构浪费内存存储。ziplist是给定大小的连续内存空间,近似数组结构,但是其数据修改涉及频繁内存操作,性能较低。list的整体使用应该遵循链表的用法,减少随机插入和更新。
 2020-11-28鱼鱼
2020-11-28鱼鱼