

当下有很多服务都使用了多数据源,或是出于跨库查询或是分库分表、读写分离等,多数据源解决方案早已不是稀罕事。常见的解决方案包括使用多数据源框架(例如Shareding-Jdbc)、在数据库端做代理(例如MYCAT)、对于固定的几个数据源连接,也可以直接手动配置多个数据源,这种相关处理有很多源码,我在github上也有简单的实现:fishstormX/dynamicDataSource: 动态数据源的实现,基于maven自定义多模块骨架。Spring Boot2.0.x,本文实现的是动态数据源,主要为了解决
实现和需求确认
本文技术能实现的是动态数据源,基于Spring框架,即能够将注入的Datasource根据租户不同使用不同的来源,同时根据租户增减动态的增删和缓存数据源(增是因为会有新增租户可能使用到项目启动后的数据源,减是因为租户数不可预料,不可直接缓存所有的数据源)。多个租户使用不同的数据源,但其Mapper(DAO层,本文基于Mybatis作为ORM框架,使用其他ORM亦可,多数据源配置与此无关)。涉及到的相关内容:
ORM框架确认(不限制,本文Mybatis);
多租户的性质和大致使用场景确认(假设单台数据源连接足够支撑,文后会讨论分布式方案); Datasource相关参数调优和连接池类型选择(大致没有出入,本文使用Druid连接池)
Datasource缓存方式和过期清除(本文使用Guava的Cache进行数据的缓存)及新增
Datasource数据拉取和上下文数据信息存储
实现方案和流程设计
从本人角度看,比较多见的
数据的读取是通过外部的配置文件,也可以通过基于API的动态查询、基于动态配置中心等方式,此部分的实现本文不详述,能确保读到新增的配置即可,当然也可以从主数据源中读取。
动态数据源的核心是AbstractRoutingDataSource,在给定实现的基础上,他可以实现动态的路由指定数据源,同时配合ThreadLocal生成标识当前数据源的Context,这样就能避免过多的手动切换数据源。
本文代码在原始基础上做了改动,不适用于所有架构,一般可能需要做些参数和细节逻辑的调整。整体流程大致如下:
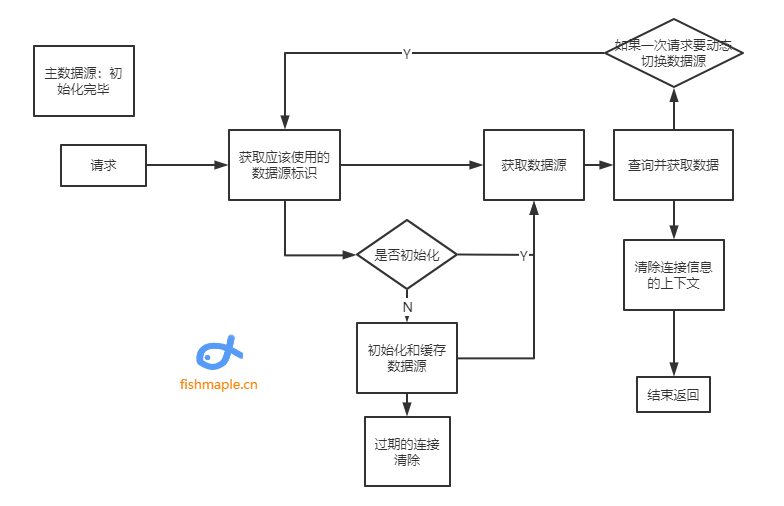
代码实现
引入依赖
需要引入数据库连接的相关依赖(包括本文使用的Druid连接池)和Guava,一般项目中会有,如没有请自行引入。
定义数据源上下文
我们必须定义一个Context,让我们自己定义的DataSource能根据当前的Context选择数据源,将
public class {
//存储上下文数据源
private static final ThreadLocal<String> dataSourceKeyMapper = new ThreadLocal<>();
//设置当前线程的数据源标识,如果为空,使用主数据源。也就是通过此方法设置数据源
//我们在这里定义为master,也可直接置为空默认使用主数据源
public static void setDataSourceKey(String uid) {
if(null==uid){
contextMapper.set("master");
}
contextMapper.set(uid);
}
public static String getDataSourceKey() {
return contextMapper.get();
}
//及时清除,以免不必要的内存泄漏
public static void clearDataSource() {
contextMapper.remove();
}
}
在要设置数据源的地方,直接调用如下方法即可(此处将数据源设置为1288),一般放在全局性的位置可以免于手动调用,譬如拦截器:
String datasourceKey = "1288"; DataSourceContext.setDataSourceKey(datasourceKey );
定义数据源配置的读取
此处实现略过,你只需要一个方法,他能根据上面的上下文读取实际的数据源配置(例如:数据host、ip、库名、username、password和一些可变参数等),你可以直接返回一个自定义对象或者定义一个Properties:
@Component
public class DbConnectConfigService{
public Properties getConfig4Db(String dataSourceKey){
^
}
}
定义数据源缓存&缓存释放
定义一处数据源缓存,Guava的Cache是线程安全的,无须担心出现冲突,而且扩展已经足够我们使用:
public class DataSourceCache {
static {
cache = CacheBuilder.newBuilder()
//设置20分钟如果没有访问则过期 以免不活跃的连接耗费资源
.expireAfterAccess(20, TimeUnit.MINUTES)
//移除时关闭数据源
.removalListener((RemovalListener<String, DataSource>) notification -> {
//清除和关闭数据源,不先执行close可能会导致不可预料的内存泄漏
DruidDataSource druidDataSource = (DruidDataSource)notification.getValue();
druidDataSource.close();
})
//还有很多配置可以自定义 尝试一下
//可以指定cacheLoader把初始化数据源的代码写在build(cacheLoader)
.build();
}
//当新增数据源时调用,以便于复用连接
public static synchronized void set(String key ,DataSource dataSource){
cache.put(key,dataSource);
}
//当获取数据源时调用,还未初始化会返回null
public static synchronized DataSource get(String key){
return cache.getIfPresent(key);
}
}
核心类:定义路由数据源和数据连接初始化
定义数据源,根据ThrealLocal初始化数据源,查询和设置缓存,注意这不是个注解注入的bean类,因为还有一些初始化工作。初始化数据时的配置相比较简陋,建议投入生产时多添加一些配置:
public class MyRoutingDateSource extends AbstractRoutingDataSource {
private DbConnectConfigService dbConnectConfigService;
//注入在构造中指定配置
public MyRoutingDateSource (DbConnectConfigService dbConnectConfigService) {
this.dbConnectConfigService= dbConnectConfigService;
}
//父类利用此方法从Context中获取数据源标识,我们调整了他的获取逻辑
@Override
protected String determineCurrentLookupKey() {
String uid = DataSourceContext.getDataSourceKey();
return uid;
}
//父类利用此方法获取当前的DataSource,其实可以直接实现在此方法中,原则上要调用super(),这里直接整体覆盖了
@Override
protected DataSource determineTargetDataSource() {
//获取数据源的key
String uid = determineCurrentLookupKey();
//务必要上锁防止单个租户出现多个数据源
synchronized (uid) {
//尝试从缓存中提取数据源
DruidDataSource dataSource = (DruidDataSource)DataSourceCache.get(uid);
//master数据源不放入cache池,
if(uid == null||"master".equals(uid)){
return super.determineTargetDataSource();
}
if (null == dataSource) {
Properties dbProperties= dbConnectConfig.getConfig4Db(uid);
//根据具体配置项初始化数据源,使用Alibaba Druid数据源
dataSource = new DruidDataSource();
dataSource.setUrl(dbProperties.getProperty("url"));
dataSource.setUsername(dbProperties.getProperty("username"));
dataSource.setPassword(dbProperties.getProperty("password"));
//一些根据实际情况要配置的东西
dataSource.setMaxWait(dbProperties.getProperty());
dataSource.setConnectionErrorRetryAttempts(2);
//使用Mysql驱动
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
try {
//手动定义的方式是没有完善的连接检查的,通过此种方式弥补,直接加载数据库连接
dataSource.getConnection();
} catch (Exception e) {
//失败的处理请自行完善,例如重试 错误码
return null;
}
//添加缓存
DataSourceCache.set(siteKey, dataSource);
}
}
return dataSource;
}
}
核心类:注入DataSource
我们将上面定义的DataSource注入取代默认的Datasource:
@Component
public class DataSourceConfig{
//默认数据源的一些配置
@Value("${spring.datasource.druid.url}")
private String url;
@Value("${spring.datasource.druid.username}")
private String username;
@Value("${spring.datasource.druid.password}")
private String password;
@Autowired
DbConnectConfigService dbConnectConfigService;
//因为有默认的Datasource,所以Primary注解不可或缺
@Primary
@Bean(name = "MyDataSource")
public MyRoutingDateSource awareRouteDataSource()
MyRoutingDateSource myRoutingDateSource = new MyRoutingDateSource (dbConnectConfigService);
//此处泛型没法改
Map<Object, Object> targetDataSources = new HashMap<>();
Map<String,String> defauleDataSourceProperties = new HashMap();
defauleDataSourceProperties.put("url",url);
defauleDataSourceProperties.put("username",username);
defauleDataSourceProperties.put("password",password);
//主数据源的设置
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setUrl(url);
druidDataSource.setUsername(username);
druidDataSource.setPassword(password);
druidDataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
druidDataSource.setTestWhileIdle(true);
druidDataSource.setTestOnBorrow(false);
druidDataSource.setTestOnReturn(false);
targetDataSources.put("master", druidDataSource);
//赋给myRoutingDateSource
myRoutingDateSource.setTargetDataSources(targetDataSources);
myRoutingDateSource.setDefaultTargetDataSource(druidDataSource);
return myRoutingDateSource ;
}
至此,所有动态切换数据源的基本功能已经实现了,但一般还需要些附加的处理。
注意事项
由于该解决方案是基于ThreadLocal的所以每当我们在代码中使用异步,需要重新设置一下数据源(DataSourceContext.setDataSourceKey(xxx))。
关于事务
大致了解Spring事务的话应该清楚,使用@Transaction注解的事务是基于方法实现的代理,通过在方法执行前开启连接,设置autocommit为false,方法执行结束进行commit的方式实现事务,如果在标注事务的方法中没有切换数据源(租户数据源和主数据源,原则上租户间不会互相切换)是没有问题的,只需要将自定义的数据源注入事务管理器。但此方式对于一个方法中切换了数据源的实现是有问题的,Spring并未提供分布式事务的解决方案,对于切换数据源的情况,基于Spring事务有缓存的原因,在事务开始阶段使用的数据源就会被锁定,进而导致后续换源失败。将datasource注入事务管理器很简单,添加了Primary注解就可以在@Transaction注解处不必指出管理器的name:
@Primary
@Bean(name="transactionManager")
public DataSourceTransactionManager transactionManager(@Qualifier("MyDataSource") MyRoutingDateSource myRoutingDateSource) {
DataSourceTransactionManager dataSourceTransactionManager = new DataSourceTransactionManager(myRoutingDateSource );
return dataSourceTransactionManager;
}
附1:通过webFilter指定数据源
通过以下的拦截器在每次请求中自动指定数据源
@WebFilter(filterName = "dbFilter", urlPatterns = {"/*"})
public class DbFilter implements Filter {
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException {
HttpServletRequest req = (HttpServletRequest) request;
HttpServletResponse res = (HttpServletResponse) response;
Stirng uid="xxxx";
//………通过参数、cookie、head等信息拿到请求对应租户的数据源
DataSourceContext.setDataSourceKey(uid);
chain.doFilter(request, response);
//用后及时清理
DataSourceContext.clearDataSource(uid);
}
}
附2:切换数据源-主数据源的AOP
一般说来主数据源是各个租户基本信息的聚合,其Mapper、SQL、表结构也应是独立的,在每次调用主数据源时都要手动指定数据源未免太蠢,可以参考动态数据源的方式,利用自定义注解实现AOP从而切换数据源
定义注解
为使其能尽可能多的适配,我定义了一个可以被继承的、可用于方法和类的注解标识此类的方法均使用主数据源:
@Inherited
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE,ElementType.METHOD})
public @interface MasterDS {
}
定义切面逻辑
使用Around切点指定和解除数据源:
@Aspect
@Component
public class MasterDSAspect {
@Autowired
MyRoutingDateSource myRoutingDateSource;
//小姿势:winthin代表类注解的方法切入,@annotation代表方法注解
@Pointcut("@within(com.xhl.autosite.common.annotion.MasterDataSource)||"+
"@annotation(com.xhl.autosite.common.annotion.MasterDataSource)")
public void masterPointcut() {}
@Around("masterPointcut()")
public Object masterAround(ProceedingJoinPoint pjp) throws Throwable {
//获取当前的数据源标识
String key = myRoutingDateSource.determineCurrentLookupKey();
if(null==key||!key.equals("master")){
//切换数据源
DataSourceContext.setDataSource("master");
}
Object object = pjp.proceed();
//恢复
DataSourceContext.setDataSource(key);
return object;
}
}
然后将@MasterDS标注在想要使用主数据源方法上即可。
 2021-01-07鱼鱼
2021-01-07鱼鱼