

业务中,数据库的设计是极为重要的一环,在高并发的业务中,我们可以采用集群部署来缓解请求和逻辑处理的压力,但是在数据库的层面却不行,Oracle、Mysql等数据库的吞吐量很高,但是依旧有阈值,我们不能奢求单库能解决所有的问题,假设遇到了数据库的瓶颈问题,我们可以采用怎样的手段呢。
解决数据库的瓶颈问题
想要数据库达到瓶颈(SQL执行效率明显变慢),其实是很困难的,我们在程序的设计中基本都会使用到数据库连接池控制数据连接,但当业务量提升之后,连接池若是经常达到饱和便容易产生阻塞,我们不得不开放更多的连接数,随之而来的便是数据库承载了更多的并发,解决问题的主要方式有三:
分库分表
更细的划分业务逻辑,将高频业务表单独分离开来,并通过定期清理的方式减小查询的执行时间,将不同的数据库请求分发到不同服务器的不同库,可以一定程度下解决上文所述的问题,但是应以数据库的设计性为前提,绝对不能牺牲原有设计合理的数据结构将其进行拆分,得不偿失。
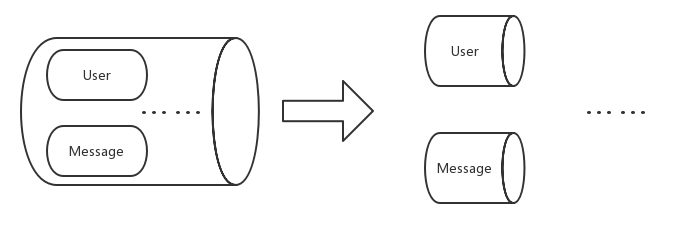
合理的分库分表,不同库之间不应存在关联,尤其不应出现跨库的查询
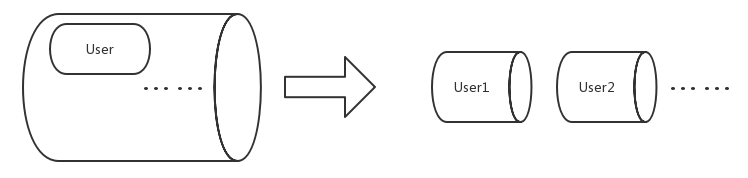
分库分表的其他措施,将不同数据(如按时间段、页数)分到不同的表中,与记录历史不同,这些库都有在业务中被访问的可能
利用缓存机制
近似于Mybatis自带的一级缓存,我们可以按业务定义缓存,将大量的重复请求在内存或是高速缓存(例如memcache、redis)的层面进行处理,譬如使用Java自带的Cache类。如何同时保证分布式服务下缓存的时效性和缓存数据的存活时间是门学问,缓存也并不适用于在所有业务,譬如某个需要保证时效性并会频繁更新的数据,每次更新时都要刷新缓存,这种业务显然不适合使用缓存。缓存的应用场景主要有二:
不奢求时效性的只要同步最近更新的数据,定期刷新(一些票务平台便是运用了这种缓存技术,否则无法承载大量的查询请求)
虽然讲求数据时效性,但是多数都是查询业务,存在热点数据(频繁的重复查询请求),并且更新数据的请求占比很小或是频率很低

缓存命中的数据会直接反回,反之则从数据库中读取
主从分离
将数据库按业务请求类型划分为读库和写库,主库用来写入,从库用来读取,一般都采用一主多从的模式,主从数据库之间会有数据同步(主从复制)因此不存在实时性的问题,与分库分表不同的是,主从分离不必介怀数据库数据表的结构设计,前者将业务进行纵向拆分,主从的分离则是按逻辑进行横向切分,他突出解决的问题是数据库整体巨大的吞吐量,而不是像缓存那样拘泥于具体的某些热点数据、某些固定的SQL语句,除此之外,主从结构的数据库也有一定的容灾性,提高整个系统的可用性。当然现在的业务中一般是三者结合使用的。
利用缓存缓解热点数据的压力
这个在我的其他文章中提到了具体的操作方式和利弊:Mybatis的缓存机制、redis数据库缓存实现和相关问题 - 鱼鱼的博客
数据库的主从同步操作
接触过才发现数据库的主从同步是MySQL自带的特性之一,在进行数据库主从配置之前,先确保我们有已经创建好的主数据库和从数据库服务和相应的账号,并尽量保持二者版本一致且已经创建好编码相同的数据库。接下来我们要进行的操作就是:
为主库分配一个账户,专门用于主从同步,建议对账户限定数据库的权限:
修改主库的配置文件,启用binlog并指定主库的server-id等
查询主库的状态,记录当前bin-log的文件位置,随后注意保证在主库不执行新的数据修改的SQL,:
SHOW MASTER STATUS;
记录下面两个内容的信息

//TODO
利用Mybatis配置多数据源
//TODO
 2019-08-29鱼鱼
2019-08-29鱼鱼