多线程应用提高(IV) 线程安全的集合类
多线程应用提高(IV) 线程安全的集合类在Java中的数据结构一篇中,列举了Java中一些常见的集合,此文主要梳理线程安全的相关集合 我们知道,当一个实例对象只能被一个线程访问时(线程私有),无论如何都不会有线程安全的问题,但在多线程的情境下,多个线程操作同一个对象时,可能会出现更新丢失、读写数据不同步、计数击穿等现象,此时这种操作就是非线程安全的 相应地,线程安全的集合有这样的特点:在多个线程操作同一集合时,能保证每一步操作都是安全的,与串行执行的结果一致,不会出现数据不同步等预料之外的问题 可以先看这个小例子Java-lab/ListT.java at master · fishstormX/Java-lab,我在里面解释了
![多线程应用提高(IV) 线程安全的集合类]()
2019-07-13鱼鱼
Java中的数据结构
Java中的数据结构若不提到Jdk版本,本文中的源码都是基于jdk8版本分析的 注:有关同步集合(如Vector、ConcurrentHashMap、CopyOnWriteArrayList等)请移步博客 数组集合类,是Collection接口的子类,有序的Collection实现,包含ArrayList、LinkedList、Vector,其中Vector是线程安全的ArrayList,LinkedList是底层基于双向链表实现的List ArrayList的默认大小为10,扩容操作: 也就是1.5倍 不重复集合类,不能包含重复的元素,是Collection接口的子类,包含HashSet、LinkedHashSet、TreeSet,其实都是基于Map类的实现,所以详细了解请参阅Map类
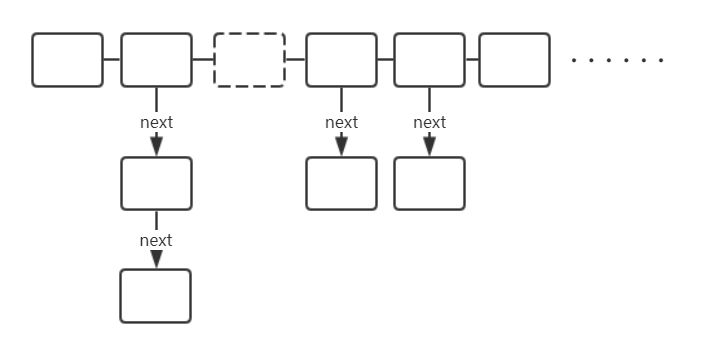
2019-07-12鱼鱼
Consul API文档
Consul API文档这是一个记录Consul 常用API的文档,因为Consul的跨语言性,所以http API在Consul中尤为重要,此文档基于Consul版本1.6.0的v1 API,有其他的变化请参阅Consul官方API文档 Consul API采用经典的rest图谱Consul API版本只有一个版本,所以所有的前缀都为 /v1/,返回值以Json格式传输,可以添加pretty参数格式化Json,以本地部署为例,整体的baseUrl为127.0.0.1:8500/v1/ 获取代理成员列表和基本信息,类似于指令'consul members' 开启维护模式后,该代理节点将会被标注为不可用,可以用于上线前临时屏蔽node的服务

2019-12-01鱼鱼
待办事宜
待办事宜2018-10-18 解决XSS攻击问题(v-html) 针对缺省有所设置(blog:page等) 添加新增按钮 添加置顶 解决日志编辑首行出现空格 开发射线:一个匿名交流板 留言 联系方式 可回复 筑楼 时限性 超时关闭 匿名 默认匿名 字典: 可标注,添加富文本新组件字典(视情况添加 工作量难以预估 可考量在全网) 字典包括 可见性(待定),条目,解释,相关词条 必须可编辑 添加不同风格 参照http://www.unconstraint.cn/,github两种风格可切换 流动 简约 重金属 使用图床存储较大的图片(RECOMMEND:使用新浪微博)
![待办事宜]()
2019-03-24鱼鱼
[Quick Start]使用RedisTemplate操作Redis
[Quick Start]使用RedisTemplate操作RedisRedisTemplate现在作为使用率最高的redis三方类库,隶属Spring技术栈,此篇文章意在指引RedisTemplate的快速上手 在实践前,请确保已经有一个可连接的Redis服务 Redis有五大基本数据类型:string、hash、list、set和zset string即是最单纯的k-v存储方式,使用set、get等指令 hash是哈希表的存储方式,比较适合用来存储对象,每一条value相当于Java的一个Map,使用hmset、hget等指令 list是简单的有序列表,每一条value相当于Java的一个List,使用lpush、lpop、rpush、rpop等指令
![[Quick Start]使用RedisTemplate操作Redis](/blog_cover/20200220/cdd943f261664778a1c746b93930db3a.png)
2020-02-23鱼鱼
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)
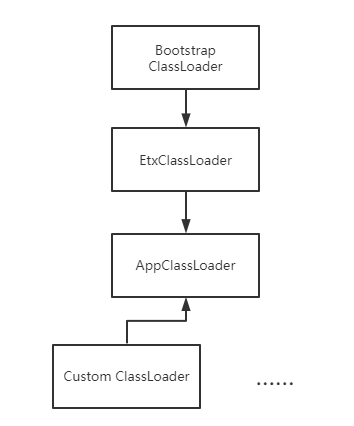
JVM源码解析 从Launcher类浅谈ClassLoader(类加载器及双亲委派)首先普及ClassLoader的基础:所有的Java类都是由ClassLoader由class文件加载进内存的,对于一个类,其唯一标识就是类名+加载他的ClassLoader(亦即对于不同的 ClassLoader,即使是加载了同一个Class也不能互通,本质上是两个类),其基本的分类如下图: BootstrapClassLoader是一个特殊的ClassLoader,负责启动时加载jre的类库 并不继承于ClassLoader,因为是jvm逻辑的一部分; ExtClassLoader也会加载jre类库,但是会加载那些额外的扩展类库(jre\lib\ext目录),到这个级别的 类加载器已经可以直接在代码中使用了;
2020-11-28鱼鱼
Spring MVC源码和设计思想3 拦截器HandlerInterceptor
Spring MVC源码和设计思想3 拦截器HandlerInterceptor系列的源码基于Java Spring 框架5.1.x版本 HandlerInterceptor是SpringMVC框架提供的独有拦截器,本身只是一个接口,提供了三个方法,方法作用情况我已标出: 有关方法执行的具体时机,可以参考Spring MVC源码和设计思想1 DispatcherServlet文中的代码 上面使用到了default关键字,default关键字是Java 8的新特性之一(之前只有用在switch中),通过default可以在接口中定义一个方法的方法体,从而使该方法不必被强制继承 Java8中也添加了static用于修饰接口方法 主要是为了考虑接口重复方法的设计,比如多个类继承与同一个接口并且需要定义相同的方法实现时,用过default或static可以避免产生重复代码
![Spring MVC源码和设计思想3 拦截器HandlerInterceptor]()
2019-06-09鱼鱼
mysql前缀索引
mysql前缀索引有时候需要索引很长的字符列,这会让索引变得大且慢 通常可以索引开始的部分字符,这样可以大大节约索引空间,从而提高索引效率 但这样也会降低索引的选择性 前面已经说过,使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本 2.1因为前缀索引无法完全等于判断,只是前缀匹配,所以可能需要扫描的所以数会增加 2.2在特殊的查询里面 select id,email from SUser where email='zhangssxyz@xxx.com'; 前缀索引需要回到 id 索引再查一下,因为系统并不确定前缀索引的定义是否截断了完整信息 select count(distinct left(email,4))as L4,

2020-05-15yangwcn
ES快速入门(2)——Tokenizer、Reindex
ES快速入门(2)——Tokenizer、Reindex本篇介绍es提供的几种分词分析器和常用的开源分词分析器 es默认的分词器,中规中矩的按照 Unicode Standard Annex #29分词,一般的小写符号会忽略,对于中文等字符会逐字分割,参数max_token_length表示最大的字符长度,再切分后会继续按此切分 譬如: 会分词为: 一个无视语义,按照字符尽量收集全索引的分词方式,会前后叠加的按符号位分词,参数: 会分词为: nGram的分词很全面,但如此夸张的方式用不好会导致索引doc过大,同时使查询效率偏低 分词规则很简单,无其余规则的按空格分词: 会分词为: 在standard的基础上能够有效拆分出邮箱和url地址的格式,同样有max_token_length这一参数:
![ES快速入门(2)——Tokenizer、Reindex]()
2020-09-05鱼鱼
DDD领域下的架构模式——CQRS架构
DDD领域下的架构模式——CQRS架构//TODO
![DDD领域下的架构模式——CQRS架构]()
2021-06-24鱼鱼
造轮子2 灵活运用反射
造轮子2 灵活运用反射//TODO
![造轮子2 灵活运用反射]()
2019-05-25鱼鱼
kasper的算法(从0到1)
kasper的算法(从0到1)https://javaguide.cn/cs-basics/data-structure/linear-data-structure.html https://javaguide.cn/cs-basics/algorithms/linkedlist-algorithm-problems.html 项目地址:https://github.com/labuladong/fucking-algorithm 在线文档地址:https://labuladong.gitee.io/algo/home/ http://fishmaple.cn/blog/topicBlog?topicId=7
![kasper的算法(从0到1)]()
2023-10-23kasper
