ES快速入门(I)——分析分词器
ES快速入门(I)——分析分词器本文旨在快速入门Elasticsearch的分词,包括分词分析器的创建和介绍对比等,请确保在阅读前已经搭建好完备的集群 文章基于es7.0+,与稍旧版本的主要区别是没有type 在讨论分词前,我们先看一下es整体创建倒排的分词过程: 我们常说的分词器指的其实是“分析器”analyzer,es将以上常用的逻辑封装起来成为analyzer,但是语义上的分词器是指上面的tokenizer 经过了三层处理后拿到了terms数组建立最终的倒排索引: character filter:一般不会用到这个filter,是在分词前对原有的文档字段内容做转换,例如去除html的标签提取出正文内容,按正则清除和替换某些内容,你可以指定及自定义0个到多个character filter,他们将共同存在,一个文本流在经过character filter处理后,依然是文本流;
![ES快速入门(I)——分析分词器]()
2020-09-01鱼鱼
算法:Trie(前缀树、字典树)
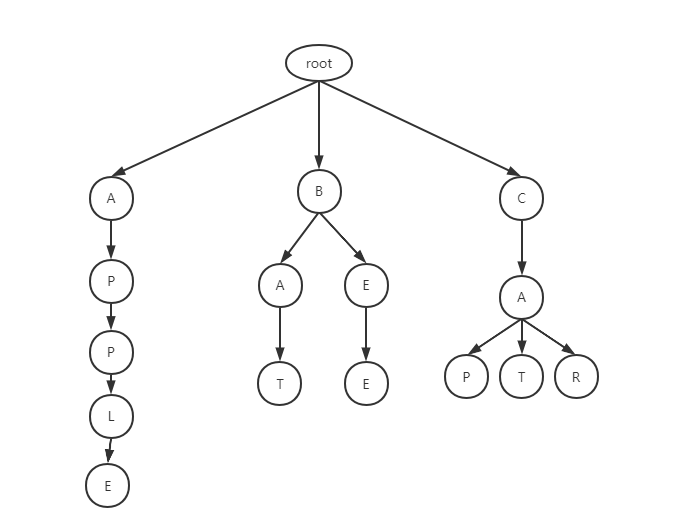
算法:Trie(前缀树、字典树)前缀树(Trie,又称字典树)是一种功能倾向性很强的数据结构,通过对词汇的前缀做数结构,很容易实现查询、前缀词推荐系统,例如,我们将如下多个单词放入树结构中: [apple,bat,bee,cat,cap,car],最终生成的前缀树结构为 通过深度递归,我们很容易用较小的时间复杂度判断出符合前缀的单词在不在 假设Trie的字符集范围是固定的,并且范围不大,例如是上面的纯英文字符,假设忽略大小写总共为26个,可以选择使用桶结构进行存储,即每一个Node都是一个长度为26的bucket数组 这样看来,Trie的结构并不复杂,只通过循环不断提高深度进行遍历即可 假定字符集的范围是未知的,或者范围很大(比如中文汉字),就要放弃使用bucket结构,而是通过一个Map维护,这里使用树结构TreeMap,key为相应节点的字符
2021-01-19鱼鱼
安全框架的使用:Shiro
安全框架的使用:ShiroShiro与Sping Security均是java的安全框架,主要用于处理用户身份验证和授权 常见场景为用户系统登录 Shiro易用性强,提供了认证,授权,加密,和会话管理功能 Shiro的三大核心组件 : Subject:即当前用户概念,不止代表着某用户,也可以是进程或任何可能的事物 SecurityManager:即所有Subject的管理者,可以把他看做是一个Shiro框架的全局管理组件,用于调度各种Shiro框架的服务 作用类似于SpringMVC中的DispatcherServlet,用于拦截所有请求并进行处理 Realm:Realm是用户的信息认证器和用户的权限认证器,我们需要自己来实现Realm来自定义的管理我们自己系统内部的权限规则

2019-09-29鱼鱼
JVM的垃圾回收
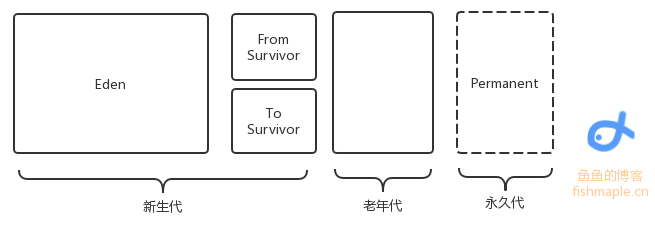
JVM的垃圾回收此文介绍Java的基本垃圾回收机制 GC主要回收的是堆区,在堆中是有对象分代的,一个对象每“逃”过一次回收,对象代数便+1,新生对象被称作新生代(如果是占据内存较大的对象直接定义为老年代),当代数一定时对象将由新生代变为老年代 同时在Java1.7之前还有永久代,保存了一些静态变量 总之,内存回收只发生在新生代和老年代之间 除了分代,内存也有分区: 如图,是内存区域分配,其中Eden存储了新建的小对象,当回收时,将Eden中存活的对象转移到To Survivor区中,将From Survivor中的代数高(一般是15)的存活对象转移到老年代中,代数没达到阈值的存活对象转移到To Survivor中
2021-04-07鱼鱼
Consul高级应用:多数据中心,模板与Client(Zuul)
Consul高级应用:多数据中心,模板与Client(Zuul)此文整理了Consul比较实用的高级功能:多数据中心,模板与维护模式 Consul提供了多数据中心联动的特性,目前看来多数据中心只是在查询阶段提现,各个数据中心的数据持久化和数据目录(k-v对)的更新不相干扰 也就是说,多数据中心的特性目前看来不能作为可用性的保障,当然 不排除可以手动热切换数据中心 最好判断是否使用多数据中心的情形是判断服务是否属于同一系统下,是否相同serviceId能提供相同的无状态服务,以下列举一些情景: 一个系统拥有多个域名的多套部署,提供版本一致的服务(建议使用多数据中心) 一个系统由多个服务器提供的不同服务提供(视服务具体情况,不建议使用多数据中心)

2020-01-28鱼鱼
JVM与GC
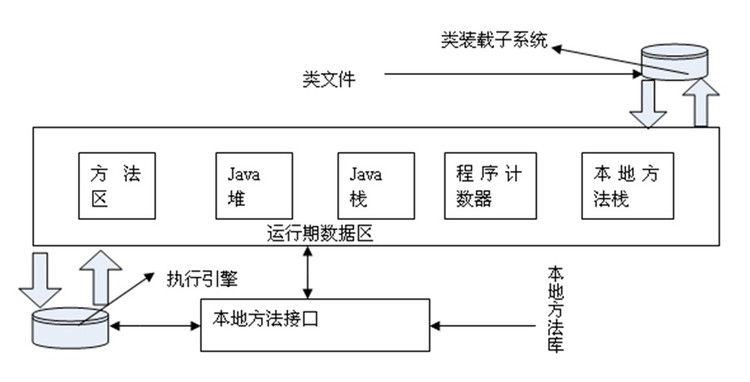
JVM与GCJMM,长下面这个样子: 其中,堆和栈区自然不做介绍了,主要介绍: 程序计数器:线程私有的,记录正在执行的字节码地址,换言之,它告诉我们某线程执行到了那里,分支、循环等也会依赖这个来执行,这一区域不会发生OOM问题 栈:就是正常所指的栈,每个方法被执行的时候都会同时创建一个栈帧(Stack Frame )用于存储局部变量表、操作栈、动态链接、方法出口等信息 每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程,这一区域会发生StackOverflow问题 堆:就是正常所指的堆,这里是GC的主要区域 方法区:线程私有的,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,运行时常量池也包含在里面
2019-03-28鱼鱼
Java的socket通信
Java的socket通信网络编程中,会使用socket通信 TCP/IP协议,即Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议,他使用TCP/IP四层模型(实际开发中只涉及到四层模型,软件范畴涉及不到OSI七层参考模型): TCP是面向连接的通信协议,通过三次握手建立连接,通讯完成时要拆除连接,由于TCP是面向连接的所以只能用于端到端的通讯 具有高度的可靠性 三次握手,即通信时,客户端和服务端共计要传输三次包,三次握手建立连接: 1.主机(客户端)发送 SYN=1(建立连接标识)和seq=x(序号),客户端进入SYN_SEND状态,等待服务端确认

2019-03-27鱼鱼
数据库的瓶颈问题解决(主从分离)与多数据源切换
数据库的瓶颈问题解决(主从分离)与多数据源切换业务中,数据库的设计是极为重要的一环,在高并发的业务中,我们可以采用集群部署来缓解请求和逻辑处理的压力,但是在数据库的层面却不行,Oracle、Mysql等数据库的吞吐量很高,但是依旧有阈值,我们不能奢求单库能解决所有的问题,假设遇到了数据库的瓶颈问题,我们可以采用怎样的手段呢 想要数据库达到瓶颈(SQL执行效率明显变慢),其实是很困难的,我们在程序的设计中基本都会使用到数据库连接池控制数据连接,但当业务量提升之后,连接池若是经常达到饱和便容易产生阻塞,我们不得不开放更多的连接数,随之而来的便是数据库承载了更多的并发,解决问题的主要方式有三: 更细的划分业务逻辑,将高频业务表单独分离开来,并通过定期清理的方式减小查询的执行时间,将不同的数据库请求分发到不同服务器的不同库,可以一定程度下解决上文所述的问题,但是应以数据库的设计性为前提,绝对不能牺牲原有设计合理的数据结构将其进行拆分,得不偿失

2019-08-29鱼鱼
网络时延、异步IO、Pipeline
网络时延、异步IO、Pipeline通过使用多线程是能提高网络延迟带来的负面效应的,也就是在IO密集型的应用中(尤其是网络IO密集应用中),通过异步操作或能显著提高性能,本篇讨论相关问题 并不是异步(多线程)定能提高性能,有这种讨论也是发现经常有人会滥用多线程 通常会有一种说法:如果想要采用多线程的来执行一段任务,为了提高性能,假设服务器中有N个核心,推荐在CPU密集型的应用中启用N个线程,而在IO密集型的任务中启用2*N个线程 本人不是很认同此种说法,他只能代表一个大致的度量,在实际应用中几乎可以说完全不准确,一般来说,权衡系统资源与性能后,前者可能需要更少的线程数,而后者根据实际情况也许适宜分配更多的线程数 这个概念大家一般都不是很陌生,在此再次科普下:所谓IO密集型任务,即是任务的资源消耗多集中在系统IO上,这里的IO本来包括磁盘IO和网络IO等,但是磁盘IO涉及文件句柄操作等系统限制不在本篇讨论,所以此篇文章所提主要指网络IO,高网络IO也是绝大多数web应用的特性
2021-04-21鱼鱼
基于Consul的服务注册与发现
基于Consul的服务注册与发现注:文章基于Consul1.6.0版本,部分版本可能会有误差 本文中项目集成部分采用Java语言 consul官网,服务注册/发现是微服务架构中不可或缺的重要组件,起初服务都是单节点的甚至是单体服务,不保障高可用性,也不考虑服务的压力承载,服务之间调用单纯的通过接口访问(HttpClient/RestTemplate),直到后面出现了多个节点的分布式架构,起初的解决手段是在服务端负载均衡,同时在网关层收束接口,使不同的请求转发到对应不同端口上,这也是前后分离防止前端跨域的手段之一: 图中的B服务也可以是多节点,注册在nginx上面的 要命的是,nginx并不具有服务健康检查的功能,服务调用方在调用一个服务之前是无法知悉服务是否可用的,不考虑这一点分布式的架构高可用的目标就成了一个摆设,解决手段也很简单:对超时或是状态码异常的请求进行重试尝试,请求会被分发到其他可用节点,或者采用服务注册与发现机制察觉健康的服务

2020-01-10鱼鱼
Spring的事务
Spring的事务Spring事务将一系列操作绑定为具有原子性的操作,此篇文章讲基于Spring提供的声明式事务 MySQL的事务我们已经明白,Spring的事务是委派了ORM框架来解决相应的问题,在jdbc中,体现的就是在Mybatis框架中,体现的就是SqlSession的建立到提交 声明式事务:在方法或是实现类上加上以下注解: 其中一些常用参数: propagation:配置事务传播行为;(后面详细解读) isolation:事务隔离级别; timeout:超时时间; roolbackFor:导致事务回滚的异常类设置; readOnly:boolean,是否只读 有七种事务传播行为,用来决策当发生事务嵌套时的解决方案
![Spring的事务]()
2019-07-18鱼鱼
多线程应用提高(II) 线程池
多线程应用提高(II) 线程池项目中,当发生并行操作时,一般都会用到线程池处理多线程任务,线程池的规则类似于数据库连接池,在此不予赘述 jdk自带线程池,此处主要讲述Spring框架自带的线程池ThreadPoolTaskExecutor 通过实现Runnable和Callable接口实现一个线程任务,从而能放入Executor进行线程管理 其中,Callable可以理解为带有返回值的Runnable,并且Callable需要实现的方法不是run()而是call(),该方法返回一个泛型对象 当我们把一个需要返回值的线程任务放进线程池后,线程池会返回一个Future对象,借助该对象,我们可以调用get()方法获取线程的状态,调用get()会阻塞当前线程直到返回结果
2020-02-25鱼鱼
