第一个Vue前端独立项目构建尝试(工程化)
第一个Vue前端独立项目构建尝试(工程化)开始我的第一个前端独立项目的构建 使用webPack、npm进行项目模块化构建 安装相关软件准备构建: VSCode npm(node) 查看版本 npm -v node -v 安装相关依赖(使用淘宝镜像): npm install -g cnpm --registry=http://registry.npm.taobao.org 安装vue-cli脚手架: npm install -g vue-cli 查看版本: vue --version 进入目录后新建vue工程: vue init webpack projectname 配置相关内容:

2019-05-04鱼鱼
多线程应用提高(II) 线程池
多线程应用提高(II) 线程池项目中,当发生并行操作时,一般都会用到线程池处理多线程任务,线程池的规则类似于数据库连接池,在此不予赘述 jdk自带线程池,此处主要讲述Spring框架自带的线程池ThreadPoolTaskExecutor 通过实现Runnable和Callable接口实现一个线程任务,从而能放入Executor进行线程管理 其中,Callable可以理解为带有返回值的Runnable,并且Callable需要实现的方法不是run()而是call(),该方法返回一个泛型对象 当我们把一个需要返回值的线程任务放进线程池后,线程池会返回一个Future对象,借助该对象,我们可以调用get()方法获取线程的状态,调用get()会阻塞当前线程直到返回结果
2020-02-25鱼鱼
分布式系统一致性的分类
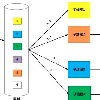
分布式系统一致性的分类在分布式系统中的CAP理论中有C(一致性),大郅表示分布式系统中节点状态或数据具有一致的特性 但一致性有着不同的分类,例如常见的用于取代CAP理论的BASE中的E,最终一致性,不同于强一致性,他强调着事务最终状态趋于一致,但中间态可能不一致,利用此篇文章总结一下分布式系统的一致性分类 根据实际系统的要求,分布式系统的一致性可以大致分为四类: 严格一致性 强一致性(线性一致/原子一致) 顺序一致性 弱一致性(最终一致性) 一个理想概念上的一致性,节点间数据完全一致,对外可表现为单个节点 由于网络延迟和通信等因素的存在,现实中这种一致性不可能存在 强一致性要求在全局时钟相同的条件下,对任何节点的读都相同且等于最后一次写成功的数据,这也就意味着仅仅在所有节点同步到数据后才会被标记为同步成功
2021-03-13鱼鱼
tips
tips一些小tip: 向上转型,失去特征 定义相同对象,重写hash和(不是或)equal Vue.nextTick() 回调函数:在Vue(重新)渲染页面之后调用 vue绑定样式,我们会发现background-color 不能直接绑定 需写为backgroundColor 因为js中不允许出现‘-’ 存库之前,mysql会把换行符什么的过滤掉,使得出入不一致(应用场景:textarea存)解决:this.value.replace(/\n|\r\n/g,"
") linux下的mysql的表名是区分大小写的! 实现线程接口 Runnable 注解注入失败 注解注入失败 Linux下缺少部分字体,使用drawString会出问题(二维码模块),解决手段:从windows引入字体,因为不是什么主流问题所以就简单写一下,如果再碰到相关问题在详细的讲述一下
![tips]()
2019-05-08鱼鱼
Spring MVC源码和设计思想序 综述
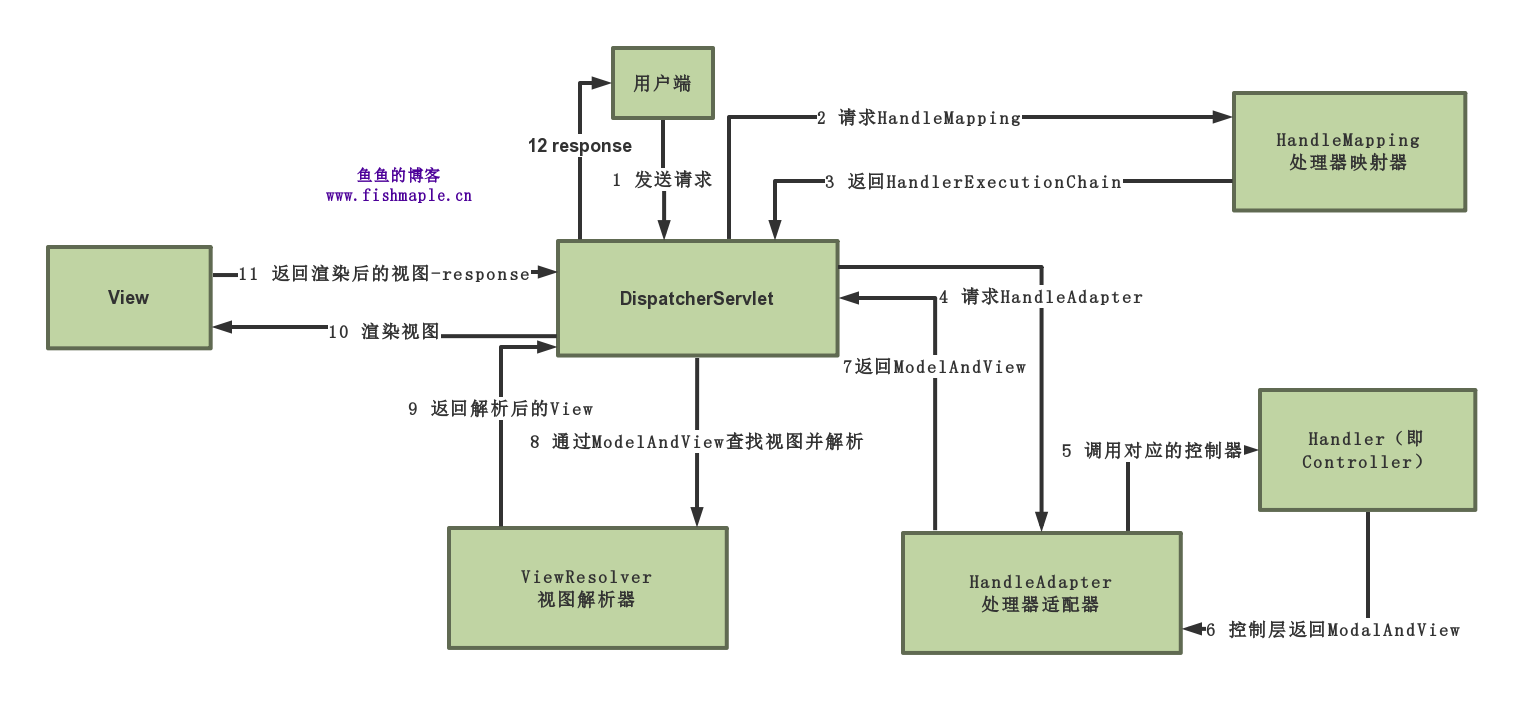
Spring MVC源码和设计思想序 综述Spring框架整体的流程:(图片引用请注明出处)
2019-06-05鱼鱼
[Quick Start]RedisTemplate的bean手动配置
[Quick Start]RedisTemplate的bean手动配置 有时我们可能需要手动配置Redis的连接,例如动态修改或是从特殊的参数中获取,而不是使用SpringBoot的自有配置,此篇文章意在快速指引redis的手动配置 基于Spring项目和Jedis的底层,使用RedisTemplate; 通过Maven引入相关依赖,可以的话spring-data-redis选择2.0.0以上版本,较低版本需要的依赖: 如果使用了Spring-boot并且要使用较高的版本(例如在2.1.0后才有的某些API-putIfAbsent带有超时时间的版本),我们直接修改starter的版本是不够的,二者版本并不对称,我们需要去掉其中的redis依赖并单独引入 建议保持良好的依赖管理习惯,显式的移除依赖,而不是任其覆盖,如:
![[Quick Start]RedisTemplate的bean手动配置](/blog_cover/20200220/bc7458d39b07471f8559d5469418133f.png)
2020-02-24鱼鱼
DDD领域下的架构模式——CQRS架构
DDD领域下的架构模式——CQRS架构//TODO
![DDD领域下的架构模式——CQRS架构]()
2021-06-24鱼鱼
Spring MVC源码和设计思想2 HandlerMapping
Spring MVC源码和设计思想2 HandlerMapping系列传送门Spring MVC源码和设计思想1 DispatcherServlet-鱼鱼的博客 此篇篇幅很长,且慢慢道来 在之前一篇中,DispatchServlet的doDispatch()方法中有这么几行: 其中getHandler方法: handlerMappings是一个初始化过的List
,通过它获取HandlerExecutionChain HandlerExecutionChain存储了一个Object(其实就是HandleAdapter)和一个拦截器(HandlerInterceptor)数组,在doDispatch方法中执行了applyPreHandle和applyPostHandle方法,方法就是分别迭代调用了拦截器数组的postHandle和preHandle,同样地,发生异常时的triggerAfterCompletion也映射到了afterCompletion方法
![Spring MVC源码和设计思想2 HandlerMapping]() 2019-06-12鱼鱼
2019-06-12鱼鱼
什么是web服务器?什么是web应用服务器?容器、以及服务器概念的区分(萌新向)
什么是web服务器?什么是web应用服务器?容器、以及服务器概念的区分(萌新向)本文主要是为了帮助萌新理解在web开发时遇到的关于web工作原理的疑问,由于本人水平十分有限,所以本文仅作为一般性参考,如有错误,欢迎批评指正OVO 首先说明的是,我们所谓的web服务器并不是物理上的服务器,而是建立在物理服务器上的一个web应用的运行环境,是一个软件服务器 这就好比前后端分离开发时,后端模块在物理服务器上的JVM,前端也需要一个“运行环境”进行工作,那么web服务器端概念就应运而生了,大概就好比下图 上图中拥有VUE经典的原谅色的web服务器就是我们前端运行的地方,可见web服务器的主要作用是给前端一个合理的运行环境,其实不只是看起来那么简单,web服务器还要处理代理、反向代理、跨域、并支持并发等等
 2019-06-16Agostino
2019-06-16Agostino
[Quick Start]使用RedisTemplate操作Redis
[Quick Start]使用RedisTemplate操作RedisRedisTemplate现在作为使用率最高的redis三方类库,隶属Spring技术栈,此篇文章意在指引RedisTemplate的快速上手 在实践前,请确保已经有一个可连接的Redis服务 Redis有五大基本数据类型:string、hash、list、set和zset string即是最单纯的k-v存储方式,使用set、get等指令 hash是哈希表的存储方式,比较适合用来存储对象,每一条value相当于Java的一个Map,使用hmset、hget等指令 list是简单的有序列表,每一条value相当于Java的一个List,使用lpush、lpop、rpush、rpop等指令
![[Quick Start]使用RedisTemplate操作Redis](/blog_cover/20200220/cdd943f261664778a1c746b93930db3a.png) 2020-02-23鱼鱼
2020-02-23鱼鱼
造轮子1 注解管理
造轮子1 注解管理使用public @interface xxx{}可以自定义一个注解,在注解上面定义的注解叫做元注解 以下代码取自开源API文档生成项目Swagger: 在注解中也可以使用注解,我们称这些注解为元注解,上面代码中使用了一些比较常见的元注解 @Target({ElementType.TYPE})用于定义注解的使用范围,常见的包含 TYPE:类、接口、枚举 FIELD:字段声明 METHOD:方法声明 PARAMTER:参数声明 CONSTRUACTOR:构造函数声明 LOCAL_VARIABLE:局部变量声明 ANNOTATION_TYPE:其他注解声明 PACKAGE:包声明(代码中的第一行 声明package的时候)
![造轮子1 注解管理]() 2019-05-25鱼鱼
2019-05-25鱼鱼
Kafka服务端集群原理
Kafka服务端集群原理kafka是家喻户晓的消息队列,也因“纯粹”而闻名(高性能高吞吐、扩展较少较为简单),此篇文章整理Kafka的基本架构,将按照Kafka的版本迭代分别展示架构的演进(截至版本3.0) 我们在这里暂且只讨论Kafka服务端,对于生产者和消费者的逻辑简单带过 扫盲一下Kafka的部分概念: Producer mq生产者通用叫法 作为消息的生产者,在生产完消息后需要将消息投送到指定的目的地(某个topic的某个partition) Producer可以根据指定选择partition的算法或者是随机方式来选择发布消息到哪个partition; Consumer mq生产者通用叫法 消息消费者,向Kafka broker读取消息的客户端;,负责订阅和消费消息
 2022-03-10鱼鱼
2022-03-10鱼鱼
