JVM与GC
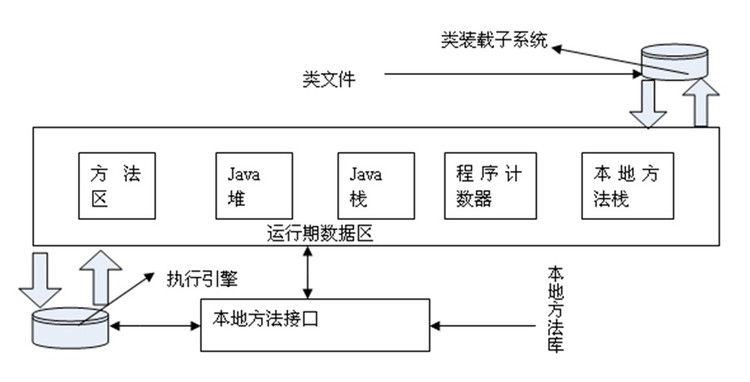
JVM与GCJMM,长下面这个样子: 其中,堆和栈区自然不做介绍了,主要介绍: 程序计数器:线程私有的,记录正在执行的字节码地址,换言之,它告诉我们某线程执行到了那里,分支、循环等也会依赖这个来执行,这一区域不会发生OOM问题 栈:就是正常所指的栈,每个方法被执行的时候都会同时创建一个栈帧(Stack Frame )用于存储局部变量表、操作栈、动态链接、方法出口等信息 每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程,这一区域会发生StackOverflow问题 堆:就是正常所指的堆,这里是GC的主要区域 方法区:线程私有的,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据,运行时常量池也包含在里面
2019-03-28鱼鱼
浅谈代理-动态代理
浅谈代理-动态代理我们可以很轻松的实现一个简单的代理 实现静态代理是个很简单的事情,最基础的代理只需要定义一个接口(虽然不是必要,但这显然才是标准的设计)、一个被代理类和一个代理类,例如: 定义一个接口: 一个实现类: 和一个代理类: 实际使用时,我们是去调用HelloWorldProxy的方法,其将作为HelloWorld的代理实现 此种方式直接实现的代理太过于死板,因为每一种代理行为都要制定一个代理类,我们熟知的很多基于代理的实现(譬如AOP、事务)显然不可能用静态代理的方式针对每一处类切点都覆写一个代理类,这种时候就需要动态代理 我们所熟知的相当多的框架均基于动态代理开发,JDK本身基于反射(java.lang.reflect)提供了动态代理,我们只需定义代理的行为,而对于代理类的范围并不是固定值
![浅谈代理-动态代理]()
2020-10-13鱼鱼
Rocket MQ的基本应用
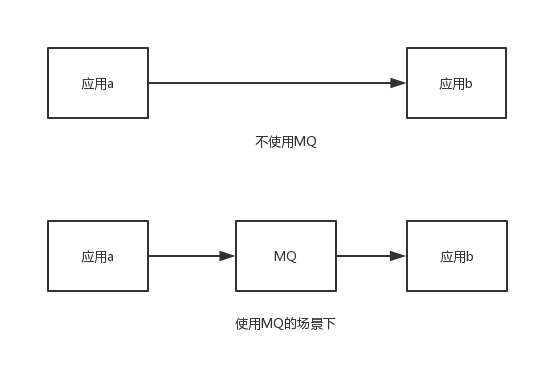
Rocket MQ的基本应用消息队列,常用于应用间通信 本篇文章基于RocketMQ官方文档 Topic:消息分类,依靠topic来定义消息类型 Tag:消息二级分类,可选,同个topic用不同的tag区分消息类别 Message : 泛指MQ所传送的消息体 Producer:消息生产者 Consumer:消息消费者 Name Server:有点类似于zookeeper,负责服务的注册与发现,维护Broker与Topic的映射关系 Broker:负责消息的存储与生产者消费者消息接收与分发,与Name Server建立长连接,保持心跳上传负责的topic信息 Producer:消息生产者,从Name Server获取Broker对应Topic映射关系,然后与Broker建立连接发送消息
2019-06-28鱼鱼
Spring MVC源码和设计思想序 综述
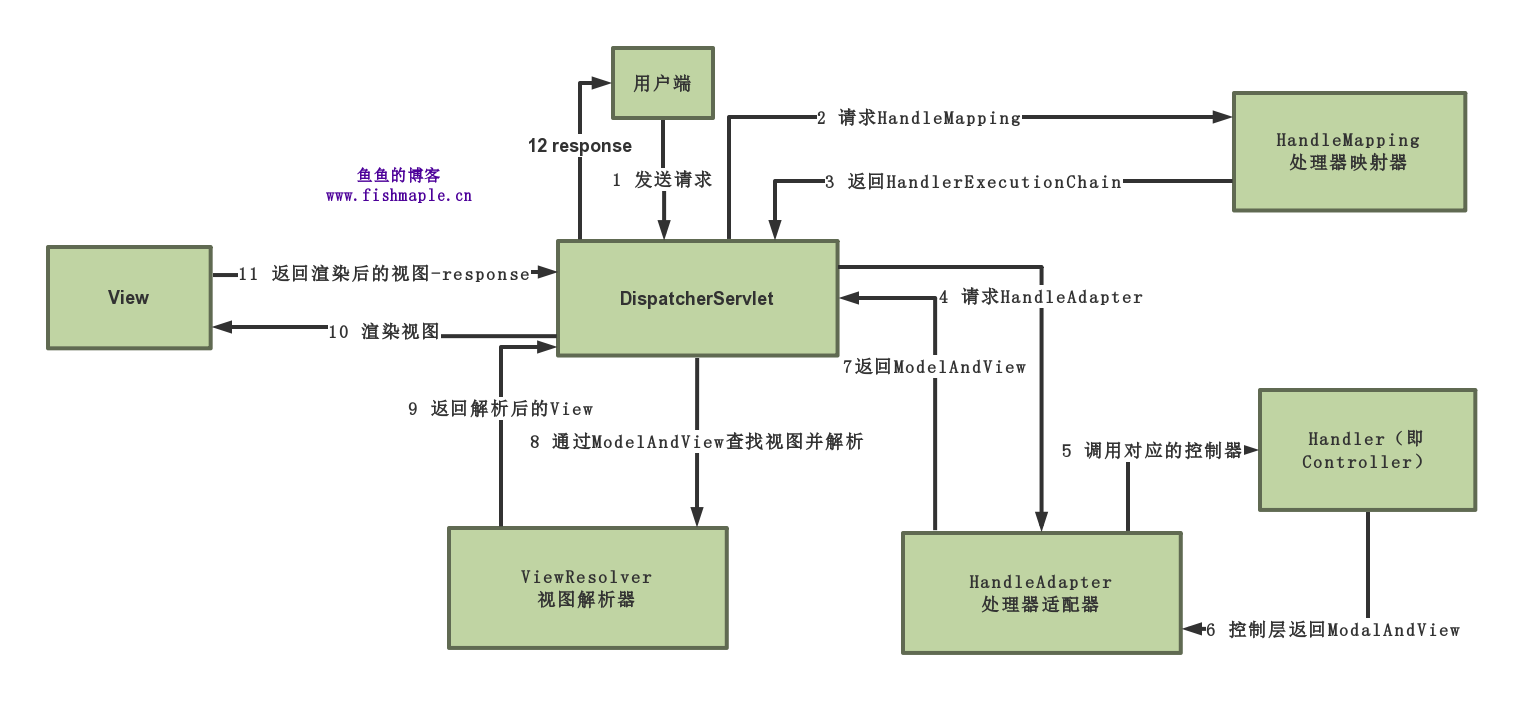
Spring MVC源码和设计思想序 综述Spring框架整体的流程:(图片引用请注明出处)
2019-06-05鱼鱼
Java的SPI机制
Java的SPI机制SPI(Service Provider Interface) 是JDK内部提供的一种用于服务能力扩展的机制 在服务中通过不同的下沉方法实现能够加载不同的接口实现类,从而实现功能的热插拔 相比一些类似的设计模式(例如策略模式), SPI作为Java自带的实现特性,相对更加灵活和开放 我们常见的JDBC、日志框架slf4j、JavaMail、Spring等组件都基于 SPI实现(例如JDBC针对不同数据源的驱动) 之所以说区别于Java的一些设计模式,因为Java有一些实现能实现 SPI的动态加载 首先让我们定义 SPI对外提供抽象能力的接口类,这里为了便于理解展示包路径:
2024-10-14鱼鱼
IO多路复用模型:select、poll、epoll对比
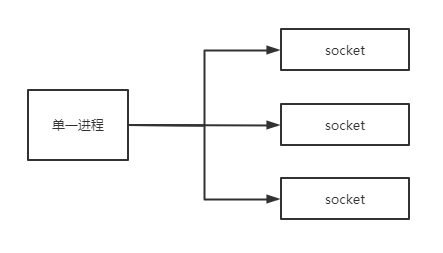
IO多路复用模型:select、poll、epoll对比我们平时提到的I/O几乎都是同步 阻塞模型,譬如网络请求的socket IO,在数据返回前,相应的线程或是进程将会一直 阻塞直到数据返回,比较直接的处理便是针对IO流一对一的监听,但在IO返回前,相应的系统资源会平白无故的浪费,这种处理方式会大大降低服务器的吞吐 如果我们用很少的线程来监听这些IO,就能实现对系统资源的更好利用,在相应的socket有数据返回时才去读取数据 这种方式被称作IO多路复用,在Linux系统中,实现IO多路复用的方式(从古老到新)有select、poll和epoll 现在很多中间件都使用epoll IO多路复用模型才因此有着很高的性能和吞吐 此处简单描述三种方式的实现和区别
2020-08-11鱼鱼
ES快速入门(I)——分析分词器
ES快速入门(I)——分析分词器本文旨在快速入门Elasticsearch的分词,包括分词分析器的创建和介绍对比等,请确保在阅读前已经搭建好完备的集群 文章基于es7.0+,与稍旧版本的主要区别是没有type 在讨论分词前,我们先看一下es整体创建倒排的分词过程: 我们常说的分词器指的其实是“分析器”analyzer,es将以上常用的逻辑封装起来成为analyzer,但是语义上的分词器是指上面的tokenizer 经过了三层处理后拿到了terms数组建立最终的倒排索引: character filter:一般不会用到这个filter,是在分词前对原有的文档字段内容做转换,例如去除html的标签提取出正文内容,按正则清除和替换某些内容,你可以指定及自定义0个到多个character filter,他们将共同存在,一个文本流在经过character filter处理后,依然是文本流;
![ES快速入门(I)——分析分词器]()
2020-09-01鱼鱼
Consul高级应用:多数据中心,模板与Client(Zuul)
Consul高级应用:多数据中心,模板与Client(Zuul)此文整理了Consul比较实用的高级功能:多数据中心,模板与维护模式 Consul提供了多数据中心联动的特性,目前看来多数据中心只是在查询阶段提现,各个数据中心的数据持久化和数据目录(k-v对)的更新不相干扰 也就是说,多数据中心的特性目前看来不能作为可用性的保障,当然 不排除可以手动热切换数据中心 最好判断是否使用多数据中心的情形是判断服务是否属于同一系统下,是否相同serviceId能提供相同的无状态服务,以下列举一些情景: 一个系统拥有多个域名的多套部署,提供版本一致的服务(建议使用多数据中心) 一个系统由多个服务器提供的不同服务提供(视服务具体情况,不建议使用多数据中心)

2020-01-28鱼鱼
并发之AQS全解析
并发之AQS全解析我们知道juc(java.util.concurrent)包下有很多实用的类,提供了很多并发工具,例如线程池、原子类、并发工具、信号量工具、锁等,可以说基本实现都为悲观锁,底层原理基本都使用了AQS(AbstractQueuedSynchronizer),AQS不是一种概念,是并发中实打实的工具类 本篇文章针对AQS做解析 AQS是多线程访问共享资源的同步器框架 AQS的资源可以是独占的也可以是共享的 我们先来简单看一下它的使用方式和ApI(因为是抽象类,是不能直接使用的),下图是AQS的整体脉络 AQS核心就是一个状态值state,同时维护了一个线程的阻塞队列,队列的节点为有两种状态:SHARED(共享)和EXCLUSIVE(独占),节点状态有五种:
![并发之AQS全解析]()
2021-03-12鱼鱼
Java中的数据结构
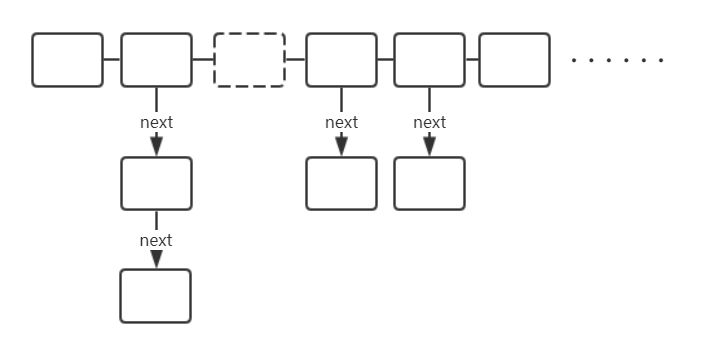
Java中的数据结构若不提到Jdk版本,本文中的源码都是基于jdk8版本分析的 注:有关同步集合(如Vector、ConcurrentHashMap、CopyOnWriteArrayList等)请移步博客 数组集合类,是Collection接口的子类,有序的Collection实现,包含ArrayList、LinkedList、Vector,其中Vector是线程安全的ArrayList,LinkedList是底层基于双向链表实现的List ArrayList的默认大小为10,扩容操作: 也就是1.5倍 不重复集合类,不能包含重复的元素,是Collection接口的子类,包含HashSet、LinkedHashSet、TreeSet,其实都是基于Map类的实现,所以详细了解请参阅Map类
2019-07-12鱼鱼
用Quartz 写定时任务
用Quartz 写定时任务Quartz是OpenSymphony开源组织在Job scheduling领域的一个开源项目,是一款清新友好的任务调度框架 Quartz两大基本功能是job和SimpleTrigger(作业和触发器) 核心的是Scheduler类 有以下几个相关类: Scheduler:定时任务调度; Job:任务类需要实现的接口; JobDetail:Job的实例,被Scheduler执行的是JobDetail,而不是Job; Trigger:触发Job的执行; JobBuilder:定义和创建JobDetail实例的接口; TriggerBuilder:定义和创建Trigger实例的接口;

2019-06-18鱼鱼
造轮子2 灵活运用反射
造轮子2 灵活运用反射//TODO
![造轮子2 灵活运用反射]()
2019-05-25鱼鱼
