

通过使用多线程是能提高网络延迟带来的负面效应的,也就是在IO密集型的应用中(尤其是网络IO密集应用中),通过异步操作或能显著提高性能,本篇讨论相关问题。
异步操作能提高性能的情景
并不是异步(多线程)定能提高性能,有这种讨论也是发现经常有人会滥用多线程。通常会有一种说法:如果想要采用多线程的来执行一段任务,为了提高性能,假设服务器中有N个核心,推荐在CPU密集型的应用中启用N个线程,而在IO密集型的任务中启用2*N个线程。本人不是很认同此种说法,他只能代表一个大致的度量,在实际应用中几乎可以说完全不准确,一般来说,权衡系统资源与性能后,前者可能需要更少的线程数,而后者根据实际情况也许适宜分配更多的线程数。
IO密集型和CPU密集型
这个概念大家一般都不是很陌生,在此再次科普下:所谓IO密集型任务,即是任务的资源消耗多集中在系统IO上,这里的IO本来包括磁盘IO和网络IO等,但是磁盘IO涉及文件句柄操作等系统限制不在本篇讨论,所以此篇文章所提主要指网络IO,高网络IO也是绝大多数web应用的特性。常见的数据库查询、后台接口请求等都为网络IO。网络IO密集型也并非总是需要依赖多线程优化,譬如若是通信都在一个局域网下或是本机(举个栗子:两台同一地区的阿里云服务器依赖内网ip进行通信),服务间请求和数据库查询速度本就非常快,直接开启很多线程来提高性能则很不可取。而CPU密集型任务则很好理解,一段复杂的算法,一个复杂的正则,需要不断调用CPU进行运算的就是CPU密集型,它的特点是消耗了本机的CPU资源,由于在Java中我们很难控制系统线程与CPU的映射关系,在CPU密集型应用中开启较多的线程会显得臃肿,性能可能也会下降。
查看值得被优化的IO密集任务-网络时延&通信时间
之前的业务中会有服务间反复请求的案例,由于Java应用自然是阻塞IO,即常规情况下进行的IO操作一般都会阻塞当前执行的线程,直到等待到请求结果返回,这样一来就不得不考量IO通信的阻塞时间了。有很多解决方式或是异步化框架能化解这种尴尬,我们后面再说。
举个例子,出于避免数据倾斜和有效利用数据缓存,有些公司会禁止使用join语句,其实这也应该基于服务间通信延迟低的前提,服务间请求同理,若是未提供批量查询只能单条串行查询,可能服务间的网络延迟/通信时间很难被忽略,这一点,在美团技术团队稍早一篇博客性能优化模式 - 美团技术团队也有提到。要查看通信延迟,一般通过ping或是traceroute命令可以知晓大概,关于traceroute大概如下,会显示跳转路由经过的每个ip和udp大致数据包传输用时(有些会被运营商屏蔽所以只能表示大致时间),下图中是一个示例(时间是表示发起了三次数据包分别统计的时间):
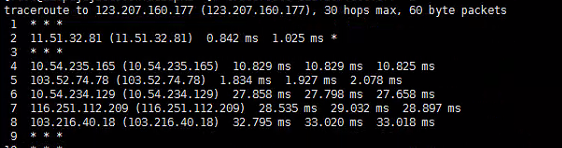
上图中的延迟便是不可忽略的,假设两服务通信延迟为100ms,即使请求处理可能只需要几到十几毫秒,一个任务中有10次请求,就会因为延迟白白损耗1s时间。同理,若请求本身便很耗时,IO的多次等待时间是可以合并的。
大致上,若是慢请求(比如批量的1s以上请求)、高延迟(一般来说,不在一个局域网下视为高延迟)是比较适合使用异步和多线程进行优化的。但以上必须基于不影响远端应用为前提,譬如使用多线程发起了批量的数据库查询或更新请求,致使某些数据被锁或是占用了MySQL服务器很高的资源比例使之硬盘IO达到瓶颈,则为了不影响其他服务,仍应使用串行,切记。
藉由异步/多线程操作提高性能
我把这种操作理解为一种设计模式,此处的异步与多线程其实又是不同的。多线程是将多次请求的延迟和通信时间归并为一次,理想情况下,总阻塞时间=请求时间最长的一次请求时间,这有点类似于多个水龙头打水,用时以最慢的为基准,当然实际根据系统损耗和线程时间片损耗"同时打水数"会有所调整。而异步是一种数据预加载的方式,譬如通过使用Future,在数据请求发起时我们并不需要它,此时主线程仍会执行其他任务,在需要数据的地方再阻塞并尝试等待获取数据,可能这时数据已经返回,便不需要等待IO时间。这在web应用中使用非常广泛。以下是几个例子。
将多个请求合并-并发请求模型
曾经写过一些同步逻辑,因为某些服务没有批量查询的功能,服务间请求可能需要调用不止一次接口,且有一定耗时。
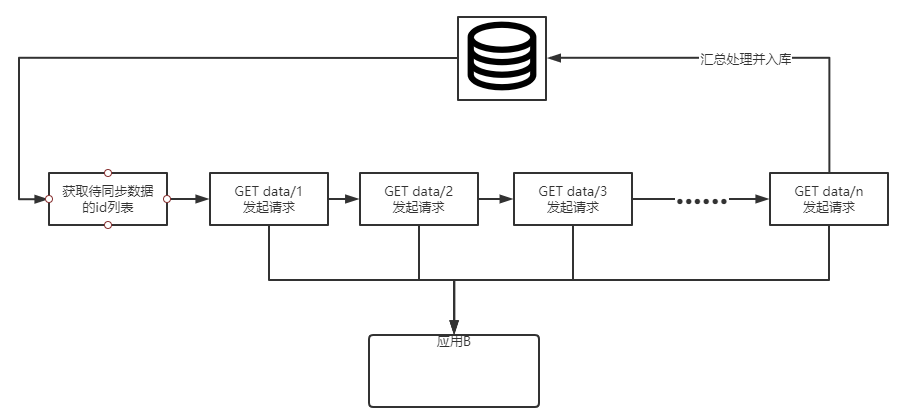
逻辑非常简单,我们可以去掉繁琐的数据处理流程,其整体流程图近似上图。而整体时序大概如下图左:大量的串行请求消耗了大龄不必要的时间。我们可以利用并发请求模型优化为图右。
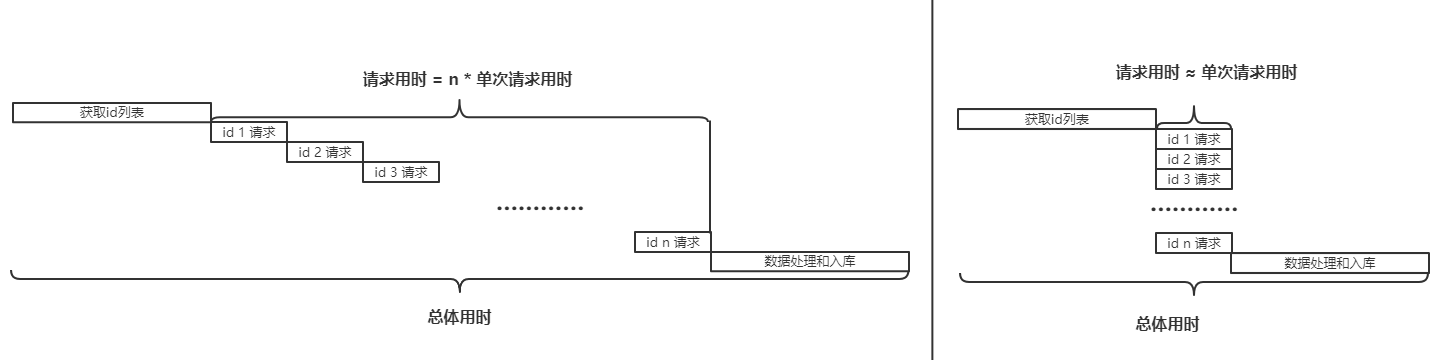
当然,由于更多的资源占用和切换时间片的消耗,并不是请求的线程越多越好。一般来说,单次请求的耗时越久,便可以使用越多的线程,在一次同步数据的task中,我也曾经同时开启过几百个线程进行同步,因为单次请求可能会耗时几十秒,通过并发请求效率会大大提高。当然也要注意远端服务的吞吐是否会因此受到影响,根据此衡量一个适中的线程数即可。以下是示例代码,不拘泥于实现方案,可以选用Future、线程池、CountDownLatch等方式。
首先可以先定义一个线程池的工具类:
public class ThreadPoolUtil {
private ThreadPoolUtil(){
}
private static ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
static{
//我们的任务并发数 使用100 已知是批量调用的情况下可以直接初始化100个线程
taskExecutor.setCorePoolSize(100);
taskExecutor.setMaxPoolSize(100);
//任务队列最大长度,在请求量未知的情况下 可以不设置,使其保持为最大
//taskExecutor.setQueueCapacity(50);
//理论上不会触发
taskExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
taskExecutor.initialize();
}
public static void addTask(Runnable task) {
taskExecutor.execute(task);
}
//Callable任务
public static Future addReturnedTask(Callable task){
return taskExecutor.submit(task);
}
}
然后编写并发请求,这里利用countDownLatch收集结果并放入一个list:
CountDownLatch countDownLatch = new CountDownLatch(urlList.size());
List<String> resultList = new ArrayList<>();
for(String url:urlList){
ThreadPoolUtil.addTask(()->{
try{
//当然 最好设定一个请求超时时间
String content = new RestTemplate().getForObject(url, String.class);
if(null==content){
resultList.add(content);
}
}catch(Exception e){
logger.error("requestError",e);
}finally {
countDownLatch.countDown();
}
});
}
//等待全部执行完毕
countDownLatch.await();
非阻塞,并在需要时阻塞(pipeline)-异步请求模型
上文中的并发请求适用场景其实不多,web应用中更多的场景IO请求为数不多,但可能相对耗时,尤其对于要大量处理或是运算数据的情况,如果调整为异步便会节省请求时间,这样可以预先发起请求,然后在结果返回前程序可以先做一些不依赖此返回数据的工作以充分利用cpu,并在需要的地方停下来等待结果返回。大致原流程如下图左,优化后为图右:
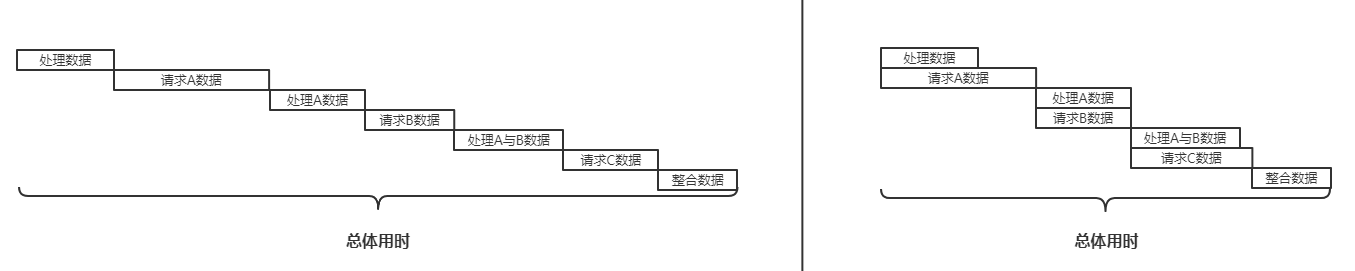
上图并没有使用并发,这能避免给他所请求服务(数据库或其他服务)带来过高的压力,通过异步,总体用时减少了很多的等待时间。例如在下面的代码中(沿用上面的线程池):
//处理数据
//请求A数据
//处理A数据
//请求B数据
//处理A与B数据
//请求C数据
//整合数据
/**
* 调整后
* */
//处理数据
Future futureA = ThreadPoolUtil.addReturnedTask(()->{
//请求A数据
return A;
});
//处理A数据
Future futureB = ThreadPoolUtil.addReturnedTask(()->{
//请求B数据
return B;
});
XXX A= futureA.get();
XXX B= futureB.get();
//处理A与B数据
Future futureC = ThreadPoolUtil.addReturnedTask(()->{
//请求C数据
return C;
});
XXX C= futureC.get();
//整合数据
这种模式使用非常广泛,比如常见语言客户端的pipeline(例如redis pipeline)通过发起多个请求并一起收集减小IO延迟带来的影响。Java一些框架也是为异步请求而设计的,利用stream流形式的API将业务改造成异步,例如web层框架webflux(基于Reactor框架)、数据层框架r2dbc或Jasync-sql,二者结合基本可以实现业务IO的全异步。但是一般情况下这种stream格式的API所带来的性能和吞吐远不及难用晦涩的API带来的负面影响大,只有在极端情况下才会使用这些框架,更多时候web应用开发看重的是研发效率而非执行性能。