

IO多路复用
我们平时提到的I/O几乎都是同步
如果我们用很少的线程来监听这些IO,就能实现对系统资源的更好利用,在相应的socket有数据返回时才去读取数据。这种方式被称作IO多路复用,在Linux系统中,实现IO多路复用的方式(从古老到新)有select、poll和epoll。现在很多中间件都使用epoll IO多路复用模型才因此有着很高的性能和吞吐。此处简单描述三种方式的实现和区别。
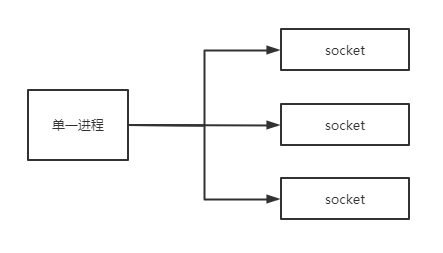
select
select可由一个固定的进程同时监听多个
poll
poll是select的简单优化,将记录
epoll
epoll为event poll,不同于轮询,epoll采用被回调的方式进行多路复用,在
每一个epoll对象都有一个独立的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件。这些事件都会挂载在红黑树中,如此,重复添加的事件就可以通过红黑树而高效的识别出来(红黑树的插入时间效率是lgn,其中n为树的高度)。
而所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,也就是说,当相应的事件发生时会调用这个回调方法。这个回调方法在内核中叫ep_poll_callback,它会将发生的事件添加到rdlist双链表中。当调用epoll_wait检查是否有事件发生时,只需要检查eventpoll对象中的rdlist双链表中是否有epitem元素即可。如果rdlist不为空,则把发生的事件复制到用户态,同时将事件数量返回给用户。
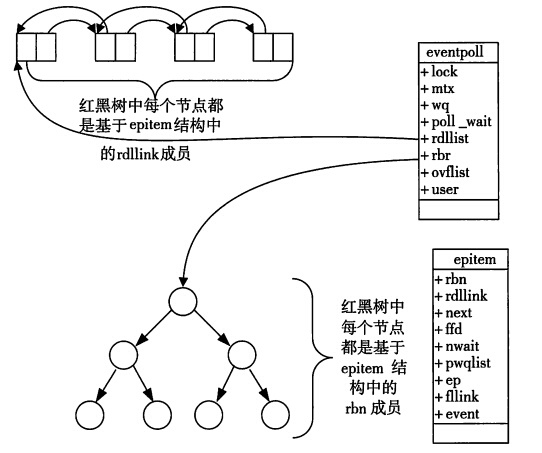
epoll整体的流程为:
epoll_create()系统调用。此调用返回一个句柄,之后所有的使用都依靠这个句柄来标识。
epoll_ctl()系统调用。通过此调用向epoll对象中添加、删除、修改感兴趣的事件,返回0标识成功,返回-1表示失败。
epoll_wait()系统调用。通过此调用收集收集在epoll监控中已经发生的事件。
参考链接:深度理解select、poll和epoll - 云+社区 - 腾讯云