

运用一些Java自带的可执行jar可以从内存的角度更轻松的排除项目中的问题,我们可能会遇到一些不常见却相对很致命的问题,例如:
-
某些web项目CPU跑到了100%并且飙高不下(一般来说,web应用都为IO密集应用,不太可能出现cpu高占用的情况)
-
项目中线程出现阻滞、阻塞(网络请求响应速度明显变慢,甚至因为死锁彻底出现阻塞等)
-
极可能由内存泄漏引发的不明原因的
OOM(没有预兆的或是基础逻辑问题的内存溢出)
当以上问题发生时,通过代码或是日志其实很难定位到原因所在,因为这一般是基于环境或资源导致的全局性问题,通常很难定位,这时可以通过使用Java自带的性能调优jar包更便捷的定位问题(如果没有配置环境变量,可以在jdk的bin目录下找到他们的jar包)。
生产环境每次出现上面的问题都是很宝贵的学习机会,在这里介绍几次我的排坑记录及相关的使用tips。
jstat
jstat是用来查看内存的加载情况的,使用格式:
jstat <-options> <vmid> [<interval(ms)> [<count>]]
其中的vimd一般使用java应用的pid。可选的参数interval和count规定了间隔多久打印options有:
(标红后面会着重解释)
-
class 查看类的加载情况(时间 数量 空间等)
-
compiler 查看编译情况
-
gc 查看垃圾回收情况
-
gccapcity 查看堆内存容量使用情况
-
gcnew 查看新生代垃圾回收情况
-
gcnewcapcity 查看新生代内存容量使用情况
-
gcold 查看老年代垃圾回收情况
-
gcoldcapcity 查看老年代内存容量使用情况
-
gcpermcapacity 查看永久代的内存容量使用情况
-
gcutil 整合垃圾回收情况
-
printcompilation 查看编译方法的统计
-gc
使用gc可以方便的查询当前各个内存空间的占用以及内存回收的概况,这是jstat最常用的指令。
对于结果中各个字段的含义为:
-
S0C:第一个Survivor的大小
-
S1C:第二个Survivor的大小
-
S0U:第一个Survivor的使用大小
-
S1U:第二个Survivor的使用大小
-
EC:Eden区的大小
-
EU:Eden区的使用大小
-
OC:老年代大小
-
OU:老年代使用大小
-
MC:
方法区大小 -
MU:
方法区使用大小 -
CCSC:压缩类空间(Compress Class Space)大小(这是元空间的一部分)
-
CCSU:压缩类空间(Compress Class Space)使用大小
-
YGC:年轻代垃圾回收次数
-
YGCT:年轻代垃圾回收总消耗时间
-
FGC:老年代垃圾回收次数
-
FGCT:老年代垃圾回收总消耗时间
-
GCT:垃圾回收消耗总时间
在下面的命令中,查看了进程号为31770的程序的各个指标,在红线的地方可以观察到触发了一次Young gc。

这是一个很健康的内存分配与回收,因为老年代的垃圾回收次数和时间都远小于年轻代,当发生以下情况时,很可能是存在内存问题,需要作出相应的调整:
-
FullGc触发的很频繁,时间或是次数并不是远小于Younggc的,但是每次回收都较为有效,回收后能有效清理内存释放空间。此时考虑内存分配不足,应调整Jvm启动参数(Xmx Xms),以避免频繁gc影响性能甚至因内存不够造成
OOM。 -
FullGc后期触发越发频繁,每次回收后老年代内存释放的很少,这种情况是内存泄漏或业务设计不合理导致,泄露的内存不能被有效回收,导致可用空间越来越小最后直至不可用,此种问题需要针对性的解决。
jstack
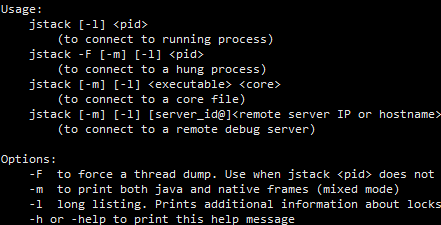
jstack可以用来显示当前jvm应用的线程状态,命令很简单:
jstack [-options] <pid>
然后大概会这样输出:

其中的java.lang.Thread.state为线程状态,有RUNNABLE、BLOCKED、WAITING、TIMED_WAITING
主要参数有:
-
-F :强制输出,默认输出的只能是活动线程,利用此参数可以获取阻塞线程
-
-l :同时输出持有的锁对象状态(synchronized),能用来判断死锁
-
-m:同时显示native的栈
问题收集1:程序cpu占用居高不下
要知道,一般的web应用都不是cpu密集型应用,我们所编写的丰富业务逻辑一般都是IO操作,很少会出现cpu长期占用很高的情况。所以当程序长久的占用cpu飙高不下,一般是程序有逻辑问题。
首先使用 top 命令查看cpu占用:
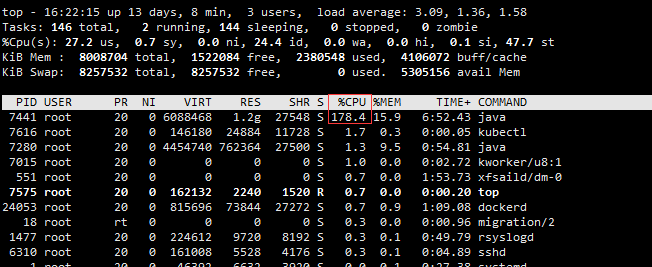
上述pid为7441的应用占用了很高的cpu,(top显示的是对应每核100%的,这是一台四核服务器,相当于快跑满了两个cpu核心),这种情况下可以利用ps -mp命令查看Linux线程的cpu占用,执行命令:
ps -mp [pid] -o THREAD,tid,time
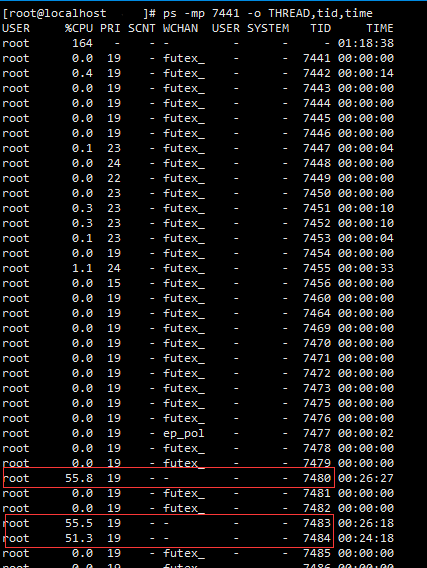
能看到有三条cpu占用很高的线程,均已经持续了20余分钟,接下来可以基于线程号用jstack查询相应线程的执行栈,jstack所输出的线程号是十六进制的,可以简单利用系统命令行做下转换,其他方式只要能获取十六进制数也可以:
printf "%x\n" 7480

使用jstack并筛选获取线程号1d38的线程状态(可能取100行还不够):
jstack 7441|grep 1d38 -A100
结果输出了:
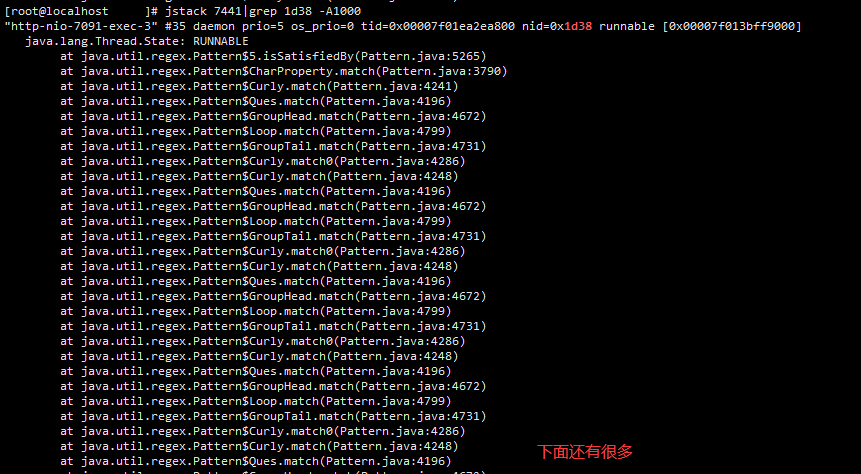
可以看到似乎在正则匹配的时候陷入了多重循环,在线程状态的最后能看到具体的代码位置。
//邮箱的正则校验 String regex = "[a-zA-Z0-9]+([.]?[-_a-z0-9]+)*@([a-z0-9]+([.-][a-z0-9]+)*\\.)[a-z0-9]+"; Pattern pattern = Pattern.compile(regex); Matcher matcher = pattern.matcher(email);
这是一个比较容易发生的问题,尤其当正则不完善遇到了匹配不符合表达式并且很长的字符串时,会进行很复杂的匹配,导致match过程占用cpu长期不释放,详细的解决可以参考博客正则表达式和 CPU 100%有什么故事?
问题收集2:程序
有些情况程序会
例如,某次服务hung状态,我们先通过ps获取其pid:

首先可以查看有无死锁,执行 jstack -m [pid] :
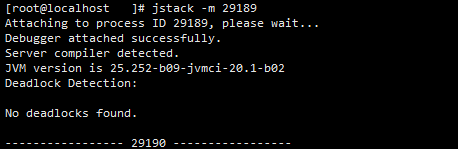
此时没有死锁,如果有较多的死锁,可以通过此种方式查看定位。接下来使用jstack查看具体的线程堆栈,在堆栈中,除去业务代码,我们发现了很多脱离业务的阻塞线程:
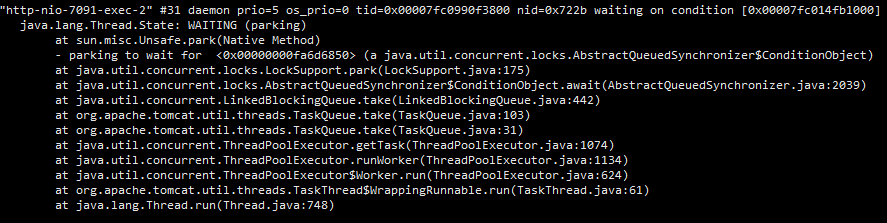
同时也有很多:
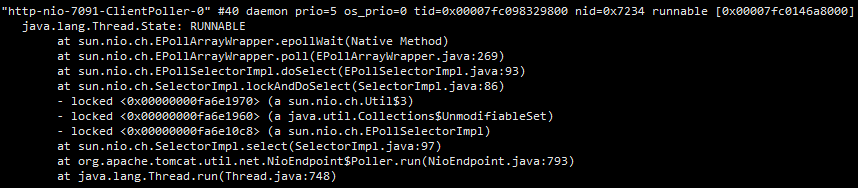
但是业务中并没有用到阻塞队列,通过检查依赖和配置项,终于找到了一个被忽略并废弃的日志xml,logback.xml:
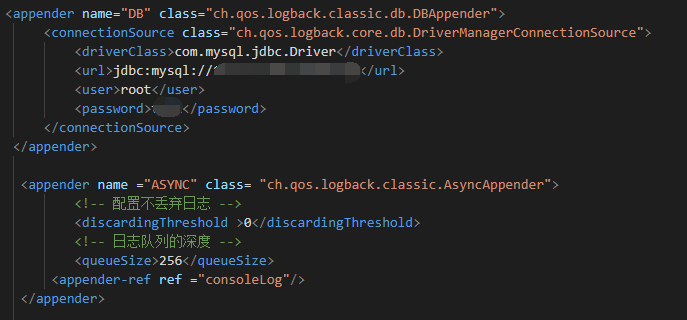
此处配置了一个异步的日志队列,队列长度为256并且不丢弃日志,当队列满时,其入队方法便会阻塞。上面配置了数据库的appender,这些异步日志会存进数据库中,如果到数据库的网络情况不好便会阻塞在这里,所以有很多take方法,即出队列,阻塞住了。一般此情况不应该使用数据库作为日志的持久化方案,不丢弃日志引起队列阻塞的设计显然也不科学,事后我们便移除了此配置,改用同步日志输出,异步日志收集的方式。
当然一个应用停住的原因不止于此,需要针对堆栈情况具体分析排查。
参考博客:【JVM】jstat命令详解---JVM的统计监测工具
 2020-11-28鱼鱼
2020-11-28鱼鱼